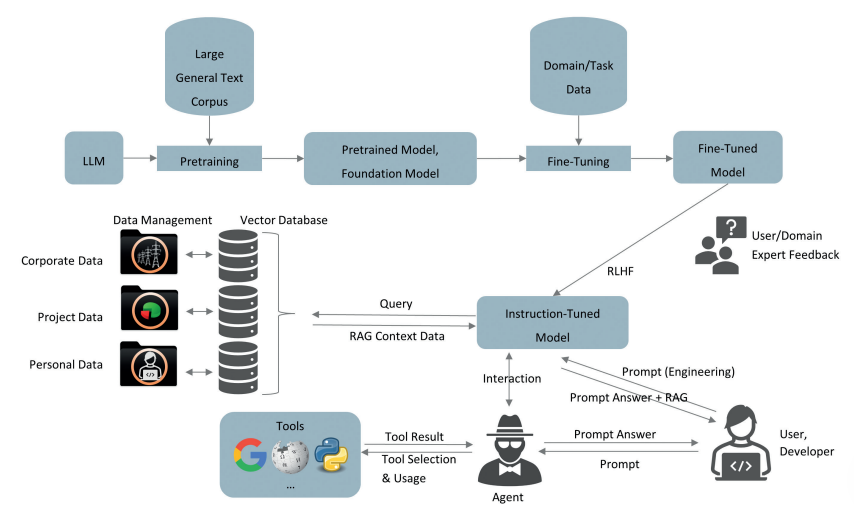
LLM and Agent
LLM and Agent
JJuprisingPrompt
prompt learning的三个要素,prompt函数,答案空间和从答案到最终结果的映射,其中prompt函数主要利用prompt将原始输入转化为带[MASK](或者占位符)的完型填空格式,答案空间主要用于搜索适合填充到[MASK]位置的候选,而从答案到最终结果的映射主要是根据填充的答案得到最终的预测结果。
Prompt learning系列之answer engineering(一) 人工设计篇 - 文章 - 开发者社区 - 火山引擎 (volcengine.com)
【NLP】Prompt Learning 超强入门教程 (zhihu.com)
文章有提到Prompt工程,有疑问指出DL就是为了避免特征工程,但是Prompt貌似又回到了特征工程。
其实可能不应该说是一个特征工程,而是因为有了LLM,下游任务和预训练的gap消失了(被称为,现代NLP第四范式)。Prompt工程能够将下游任务进行任务重定义,使得所有的NLP任务转变为语言模型问题。
思维链Cot
COT通过要求模型在输出最终答案之前,显式输出中间逐步的推理步骤这一方法来增强大模型的算数、常识和推理能力。简单,但有效。

一文读懂「Chain of Thought,CoT」思维链-CSDN博客
Agent
人机协同模式
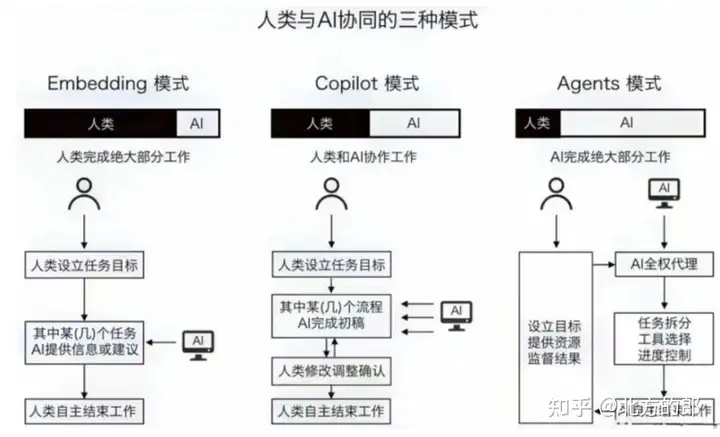
基于大模型的Agent不仅可以让每个人都有增强能力的专属智能助理,还将改变人机协同的模式,带来更为广泛的人机融合。生成式AI的智能革命演化至今,从人机协同呈现了三种模式:
(1)嵌入(embedding)模式。用户通过与AI进行语言交流,使用提示词来设定目标,然后AI协助用户完成这些目标,比如普通用户向生成式AI输入提示词创作小说、音乐作品、3D内容等。在这种模式下,AI的作用相当于执行命令的工具,而人类担任决策者和指挥者的角色。
(2)副驾驶(Copilot)模式。在这种模式下,人类和AI更像是合作伙伴,共同参与到工作流程中,各自发挥作用。AI介入到工作流程中,从提供建议到协助完成流程的各个阶段。例如,在软件开发中,AI可以为程序员编写代码、检测错误或优化性能提供帮助。人类和AI在这个过程中共同工作,互补彼此的能力。AI更像是一个知识丰富的合作伙伴,而非单纯的工具。
实际上,2021年微软在GitHub首次引入了Copilot(副驾驶)的概念。GitHub Copilot是一个辅助开发人员编写代码的AI服务。2023年5月,微软在大模型的加持下,Copilot迎来全面升级,推出Dynamics 365 Copilot、Microsoft 365 Copilot和Power Platform Copilot等,并提出“Copilot是一种全新的工作方式”的理念。工作如此,生活也同样需要“Copilot”,“出门问问”创始人李志飞认为大模型的最好工作,是做人类的“Copilot”。
(3)智能体(Agent)模式。人类设定目标和提供必要的资源(例如计算能力),然后AI独立地承担大部分工作,最后人类监督进程以及评估最终结果。这种模式下,AI充分体现了智能体的互动性、自主性和适应性特征,接近于独立的行动者,而人类则更多地扮演监督者和评估者的角色
AI Agent
agent这个词很早就出现了,在过去,有ABM(Agent-Based Model)。随着LLM出现,最近的AI Agent爆火。
ai agents或者说LLM-based agents跟普通的LLM有什么区别?
吴恩达老师的解释非常清晰:比如你想让LLM帮助写一篇文章的提纲
- 非智能体模式,输入一段prompt它给出回答,相当于让一个人在电脑前打字完成一篇提纲同时不能要求有错字。
- 智能体模式(agentic workflow),思考是否需要查阅资料,是的话就上网查找,写了一个初稿,反思哪里需要修改,继续修改,重复步骤
zero-shot prompt零样本提示(只给出一次prompt然后得到结果)的准确率是很低的,同样zero-shot的gpt3.5 acc 48%;gpt4 acc 67%带智能体工作流的gpt3.5会高于zero-shot的gpt4.
实现模式
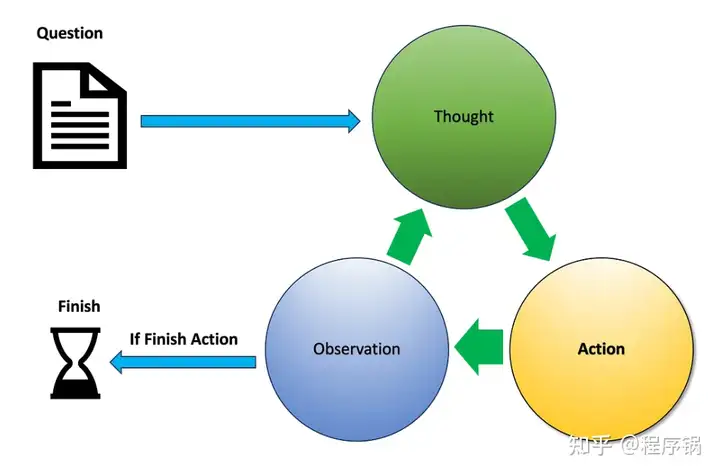
比较早的是ReAct模式——TAO循环,即思考(Thought)>行动(Action)>观察(Observation)
- Thought思考,就是LLM的推理步骤,确定LLM如何解决问题,基于思考采取Action
- Action行动,采取措施执行特定任务,推动问题向解决的方向发展
- Observation观察,行动之后观察结果,检验行动是否有效,是否接近了问题的答案。如果LLM明白它得到了答案就结束问题;否则根据观察再次进行思考产生新的想法,重复TAO直到得到答案。
回到主题上,关于TAO循环,我放上一个实操例子:
1、准备两个工具,其中一个可以通过API查询给定城市的天气信息(包括温度、体感温度、湿度和风速),输入参数为城市位置(eg.北京);另外一个可以查询当前的时间,输入参数无。两个工具的输出均是结构化json数据。
2、用户输入:今天我将从北京飞往三亚,请根据天气情况给我定制穿衣计划。
TAO循环真实案例如下:
1 | {'role': 'user', 'content': '\nQuestion:今天我将从北京飞往三亚,请根据天气情况给我定制穿衣计划'}, |
可以发现TAO循环的具体实现形式仍然是问答的形式。大模型通过思考了解需要分别调用工具查询北京和三亚的天气,并且最后在Final Answer来提出衣服着装方面的建议。
这个时候大家就有疑问了,在上述例子第三行中Observation为工具API调用的结果,那么大模型回答问题的时候为什么能够形成TAO循环、大模型是怎样从Thought到选择正确的Action并且识别出工具的Action Input呢?
这就需要提示工程以及输出数据结构化。
提示工程:构造模板,如对应工具,输入输出格式等
1 | Answer the following questions as best you can. You have access to the following tools: get_current_weather: Call this tool to interact with the 天气查询 API. What is the 天气查询 API useful for? 基于给定的城市获取天气信息,天气信息包括温度、体感温度、湿度和风速。 Parameters: [{'name': 'city_name', 'description': '城市名称', 'required': True, 'schema': {'type': 'string'}}] Format the arguments as a JSON object. get_current_time: Call this tool to interact with the 获取当前时间 API. What is the 获取当前时间 API useful for? 获取当前的系统时间。 Parameters: [] Format the arguments as a JSON object. Use the following format: Question: the input question you must answer Thought: you should always think about what to do Action: the action to take, should be one of [get_current_weather,get_current_time] Action Input: the input to the action Observation: the result of the action ... (this Thought/Action/Action Input/Observation can be repeated zero or more times) Thought: I now know the final answer Final Answer: [the final answer](https://zhida.zhihu.com/search?content_id=691408049&content_type=Answer&match_order=2&q=the+final+answer&zhida_source=entity) to the original input question Begin! |
可以看到在系统提示词中,已经将各个工具以及对应工具的输入输出定义好。此外,也告诉大模型需要按照TAO的模式输出结果。
智能体系统
内容综合自OpenAI应用研究主管LilianWeng:LLM Powered Autonomous Agents,以及吴恩达老师的演讲https://www.youtube.com/watch?v=sal78ACtGTc&t=140s
吴恩达老师列出了四个设计模式,Reflection, Tool use, Planning, Multiagent collaboration
Agent=LLM + memory + planning skills + tool use
Memory记忆:
- 所有的上下文学习(参考Prompt Engineering)都可以看成是利用模型的短期记忆来学习。
- 长期记忆:长期记忆为代理提供了长期存储和召回(无限)信息的能力,它们通常通过利用外部的向量存储和快速检索来存储和召回(无限)信息。
Planning计划
- 子目标和分解:代理将大型任务分解为较小,可管理的子目标,从而有效地处理复杂的任务。
- 反思和改进:代理可以对过去的行动进行自我批评和自我反思,从错误中学习并改进未来的步骤,从而提高最终结果的质量
tool use使用工具
- 代理通过学会调用外部API来获取模型权重(通常在预训练后很难修改)中缺少的额外信息,包括当前信息,代码执行能力,访问专有信息源等。
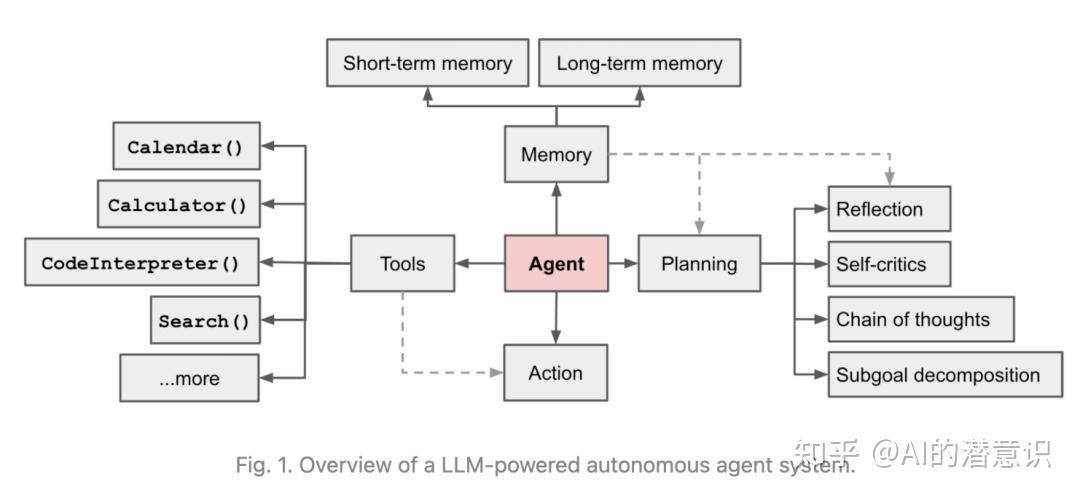
Planning
Reflection
例如让LLM给出一段代码,然后让它修改其中的bug,它会给出版本2,接着跟他说不能通过某个测试单元,它会给出版本3。
以上这个LLM为编程智能体,同时你可以设置一个评审智能体(跟他说你是评审专家,请审查代码),这就构成了一个简单的多智能体系统
Chain of thoughts思维链
Chain of thoughts思维链 (CoT; Wei et al. 2022) 已成为提高模型在复杂任务上表现的标准提示技术。模型被指示“逐步思考”,以利用更多的测试时计算将困难任务分解为更小、更简单的步骤。链式思维将大任务转化为多个可管理的任务,并对模型的思维过程的解释提供了启示。
例如你给出一张图片,想让LLM用语言描述一个女孩用图片中小男孩的姿势在读书
HuggingGPT:
1.从图片得到位姿势–2.找到处理图像的模型生成女孩–3.image-to-text–4.text-to-voice
Tree of Thoughts思维树
Lil还提到了Tree of Thoughts (Yao et al. 2023) 思维树:通过在每一步探索多种推理可能性来扩展 CoT。它首先将问题拆解成多个思维步骤,并在每一步生成多个想法,形成树状结构。搜索过程可以是 BFS(广度优先搜索)或 DFS(深度优先搜索),每个状态由分类器(通过提示)或多数投票进行评估。
Tool
例如数据收集检索,处理等等的工具
基于LangChain的Agent的代码实现
概念
代理的核心理念是使用语言模型选择一系列要采取的行动。
架构Schema
AgentAction
表示agent要执行的动作,有两个属性tool(即应该被调用的工具的名称)和一个属性tool_input(该工具的输入)
AgentFinish
agent准备返回给用户的完成结果。它包括一个键值对(key-value)的mapping,return_values。还有agent响应的字符串output
Intermediate Steps中间步骤
这些代表了当前代理运行中之前的代理操作及其相应的输出。这些对于传递给未来的迭代至关重要,以便代理知道它已经完成了哪些工作。这被输入为一个 List[Tuple[AgentAction, Any]]。请注意,观察目前被留作类型,以保持最大的灵活性。在实际操作中,这通常是一个字符串。
Agent
This is usually powered by a language model, a prompt, and an output parser.
Agent输入
代理的输入是键值映射。只有一个必需的键:intermediate_steps,如上中间步骤所述
通常,PromptTemplate负责将这些对转换为可以最佳传递给LLM的格式。
Agent输出
输出是要采取的下一个行动或发送给用户的最终响应(AgentAction或AgentFinish)。具体来说,这可以被表述为Union[AgentAction, List[AgentAction], AgentFinish]
输出解析器(output parser)负责将原始 LLM 输出转换为这三种类型之一。
AgentExecutor
代理执行器是代理的运行时。这实际上是调用代理的内容,执行它选择的操作,将操作输出传递回代理,并重复。在伪代码中,这大致看起来像:
1 | next_action = agent.get_action(...) |
工具
工具是代理可以调用的功能。工具抽象由两个部分组成:
工具的输入模式。这告诉 LLM 调用工具所需的参数。没有这个,它将不知道正确的输入是什么。这些参数应该有合理的名称和描述。
要运行的函数。这通常只是被调用的 Python 函数。
考虑事项
关于工具,有两个重要的设计考虑:
- 给予代理访问合适工具的权限
- 以最有助于代理的方式描述工具
如果不考虑这两点,您将无法构建一个有效的代理。如果您不给代理访问正确工具集的权限,它将永远无法实现您赋予的目标。如果您没有很好地描述工具,代理将不知道如何正确使用它们。
LangChain 提供了一套广泛的内置工具,同时也使您能够轻松定义自己的工具(包括自定义描述)。有关内置工具的完整列表,请参阅工具集成部分。
构建
构建一个自定义Agent,一般有五步:定义LLM推理引擎—定义tool—定义prompt—封装—添加记忆
可以用Retriever实现RAG检索自己预设的外部数据,例如某网站的文档内容等。
术语
instruction-tuned and fine-tuned model
instruction-tuned 指令调优
instruction-tuned model(指令调优模型)是一种通过特定的训练方法,优化模型在执行指令或任务时的表现的机器学习模型。简单来说,这种模型在训练过程中会特别关注“听从指令”的能力,以便在实际应用中更好地理解和执行用户的命令。
以下是instruction-tuned model的一些关键特点和训练方式:
训练数据类型:与普通的监督学习不同,instruction-tuned模型的训练数据通常包含大量指令或任务描述以及相应的答案。这些数据可能涵盖从回答问题到解释概念、生成文本等多种任务类型。
强化学习:instruction-tuned模型有时会使用强化学习(如强化学习自反馈,RLHF),以便在与人类反馈交互中不断改进。人类反馈可以帮助模型优化回答的质量和相关性。
广泛应用:这种模型通常被应用于生成式AI,比如智能对话、自动问答、代码生成、写作协助等场景。通过指令调优,模型可以更好地理解用户意图,并且在执行任务时更具一致性和准确性。
例如,OpenAI的GPT-3.5和GPT-4等模型就是通过instruction-tuning的方式来提升其在多种任务场景中的表现。
Fine-tune 微调
fine-tune model(微调模型)是一种在已有的基础模型上进行进一步训练的技术,目的是让模型适应特定的任务或领域需求。fine-tuning 是对已经经过大量数据训练的预训练模型进行定制化的调整,以便在目标任务上达到更好的性能。
fine-tuning 一般包括以下几个步骤:
选择预训练模型:首先选择一个在大规模数据集上训练过的模型(例如BERT、GPT、ResNet等),这些模型在通用任务上已经具备较好的理解或生成能力。
准备领域数据:根据目标任务(如情感分析、机器翻译、医学诊断等),收集与之相关的数据。通常,这些数据量不需要像训练基础模型时那么庞大,因为预训练模型已经掌握了基本的特征和语言模式。
设置特定任务目标:根据任务需求定义损失函数和评价指标。例如,对于情感分析,目标是预测正面或负面情绪;对于文本生成,目标是生成合适的回复。
调整模型参数:将预训练模型加载进来,通过新数据对模型进行多轮训练,以更新模型的权重参数,使其在该任务上的表现更好。
验证和优化:在验证集上测试微调后的模型,以确保其在目标任务上达到预期效果,并进行必要的优化调整。
优点:
- 高效:无需从零开始训练整个模型,只需在预训练模型上进一步训练,节省了大量计算资源。
- 适应性强:通过微调,可以将通用模型调整为特定领域的专家,从而显著提升特定任务的表现。
- 数据需求少:由于模型已经掌握了通用知识,只需少量的数据就可以让模型学习到目标任务的特定知识。
例如,GPT-3模型可以通过微调来专门为客服场景或技术支持场景优化,从而更准确地回答用户问题。这种技术在自然语言处理、计算机视觉、语音识别等领域得到了广泛应用。