CVPR 2024 Best Paper

CVPR 2024 Best Paper
JJuprisingGenerative Image Dynamics
生成式动力学 Generative Image Dynamics 谷歌团队
扩散模型在视频领域的应用
主要用于建模自然界中的震动、摇摆(oscillatory dynamics)。用频域的方法,在Fourier domain中预测运动;然后通过下游渲染模块根据生成的运动信息赋予静止图片动态。
Demo:
https://generative-dynamics.github.io/#demo
出发点
为了更加形象的视觉合成方法
人类对运动的敏感性会导致没有运动的图像看起来不真实
更真实模拟自然界中物体的运动
Generative Image Dynamics让生成的动图更具真实性
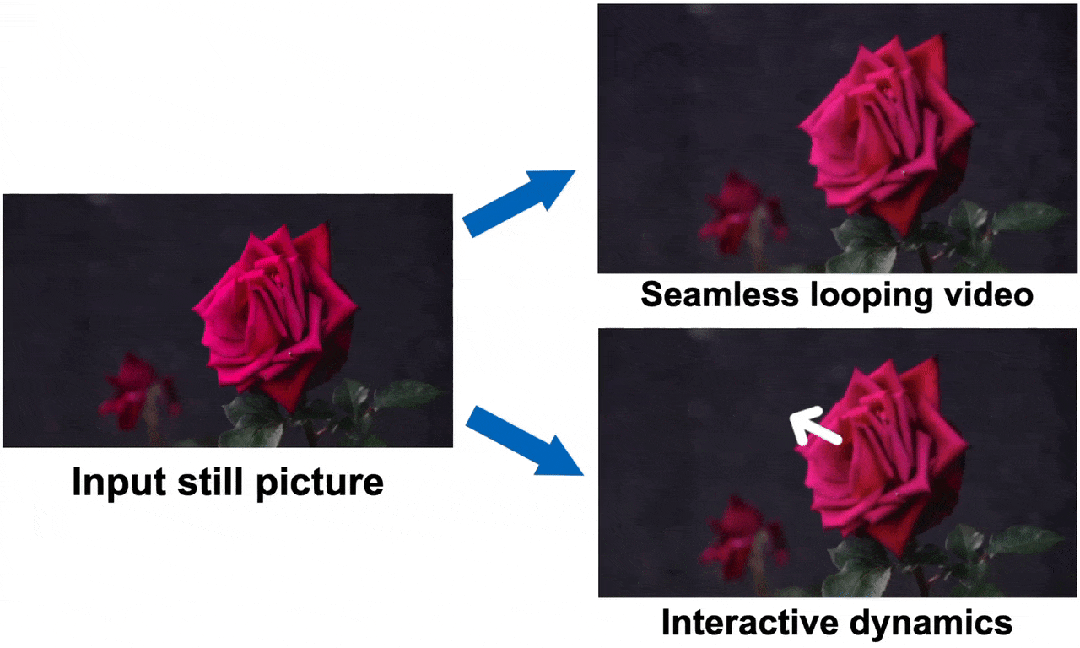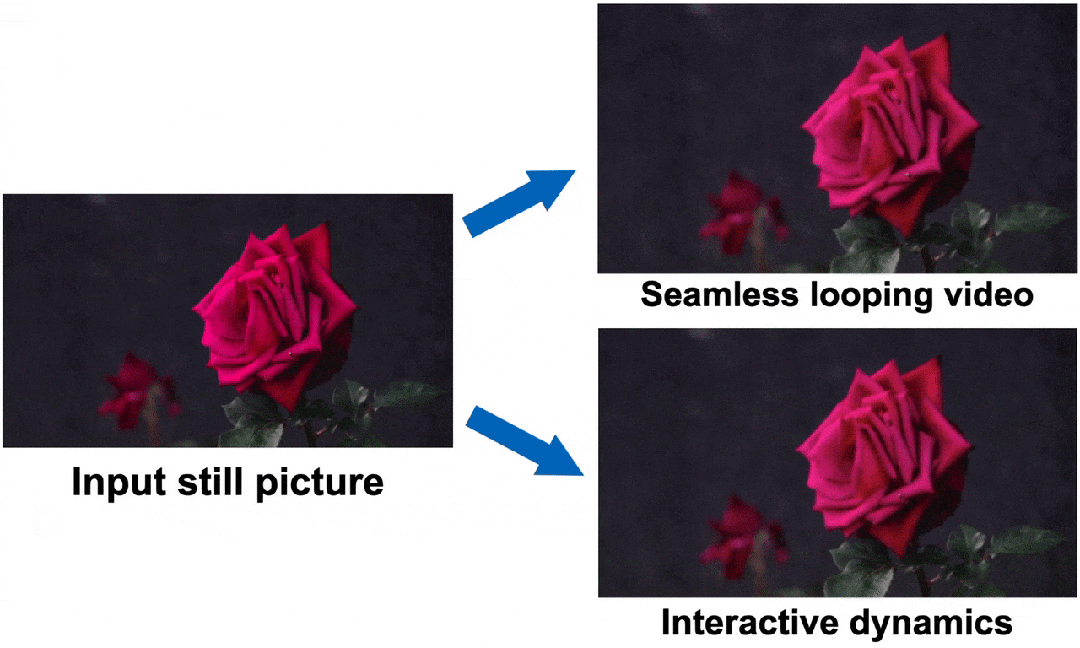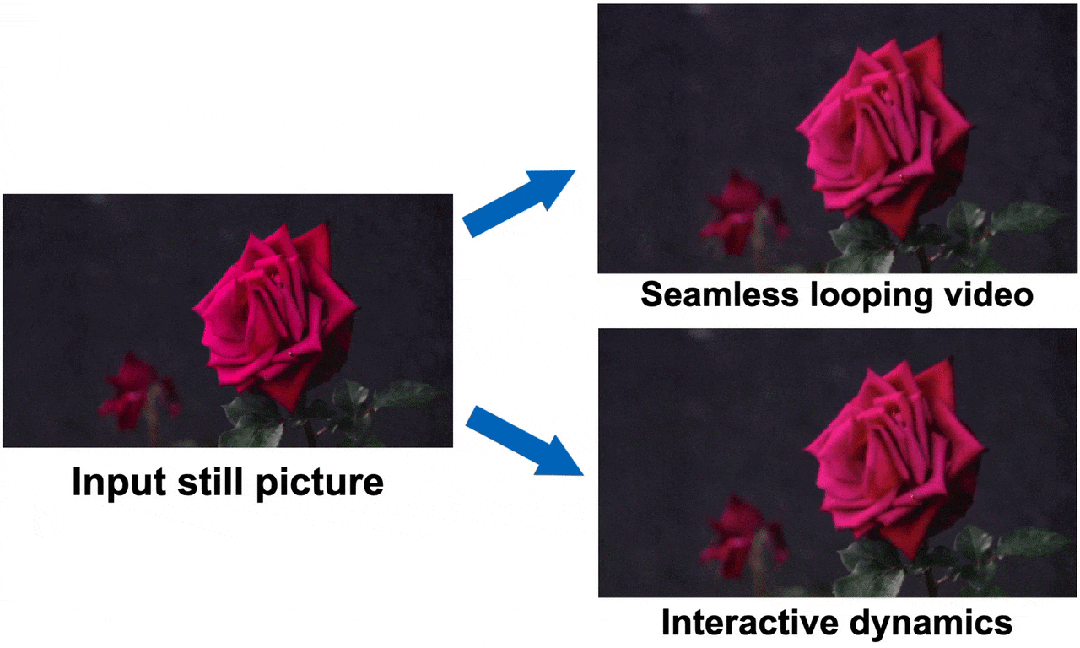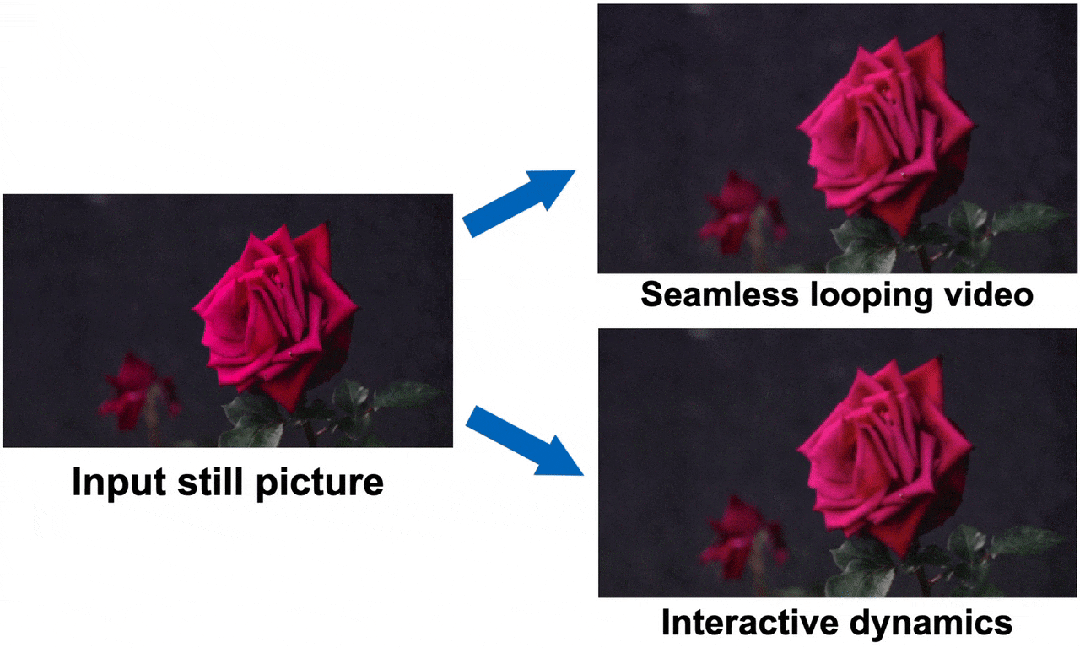
方法
输入图片->傅里叶变换->在不同频率下通过LDM模型->图像光谱->通过类似UNet模型生成后续时间的图像
那为啥扯上频率呢?更频率域有什么关系
频域分析的优势是,频域可以把不同的运动通过频域拆解开(比如频率低的运动就是一些缓慢的大范围的运动。频率高的运动就是一些快速范围小的运动),这样就可以对不同运动分别进行分析生成。类似的低频高频拆解的操作在神经辐射场里也有体现,神经辐射场把不同的输入用低频到高频的谐波进行位置编码,来获得更高频更细微的特征。
光谱分析的原因是,光谱能很好刻画运动模式。使用光谱,我们就能方便地在频域分析运动,并转换回时域生成新的图像。
运动表示
本文作者从自然界的运动开始分析,发现自然界的运动可以分解成不同频率周期的运动叠加。所以在频域中对自然运动进行建模分析。
LDM
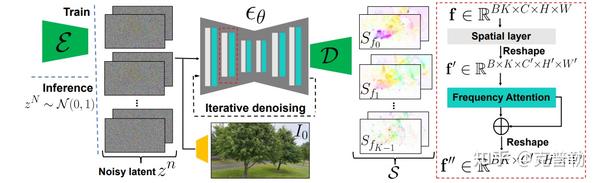
本文中的光谱预测阶段,模型使用一个 VAE(变分自编码器)作为编码器,把输入图像压缩到潜空间。然后不断去噪之后,通过解码器来得到一系列的光谱信息。此外,作者发现了运动的纹理会跨频率分布,但是在扩散模型的训练时,需要输出在 [-1, 1] 之间保证稳定训练。所以归一化是必不可少的,但如何归一化呢,简单的缩放会导致高频信息的损失。作者采用了一种频率自适应归一化来维持高频信息
右图为频域注意力,采用[**cross attention**](https://www.zhihu.com/search?q=cross attention&search_source=Entity&hybrid_search_source=Entity&hybrid_search_extra={“sourceType”%3A”article”%2C”sourceId”%3A”666152573”})实现不同频域的交互,实现频域的一致性
基于图像的渲染方法
得到光谱后,要输出下一帧图像,利用傅里叶反变换得到!(逆过程)
Limitations
非振荡运动:可能无法有效建模非振荡运动。
高频振动:可能无法准确捕捉高频振动。
基础运动轨迹:生成视频的质量高度依赖于基础运动轨迹的质量。在以下场景中可能会出现质量下降:
- 细小的移动物体。
- 大位移的物体。
未见过的新内容:需要生成大量未见过的新内容的运动也可能导致质量下降。
总结
文本通过频率协作的潜在扩散模型来预测光谱体积,并通过图像渲染模块来生成未来的视频帧。作者展示了该方法能够从单张图片中生成逼真的动画,并显著超越了之前的基准方法,还可以实现无缝循环或图像交互等下游应用。是一篇很有实用意义的论文。
Rich Human Feedback for Text-to-lmage Generation
解决的问题
论文试图解决T2I(Text-to-Image)生成模型在生成高分辨率图像时仍然存在一些问题,例如现实规则不一致(图像中的伪影与不合理性)、图文语义不一致(与所提供的提示词描述不一致)、美学期望不一致(生成的图像具有低审美质量)。为了改善这些问题,论文提出了一种通过丰富人类反馈来改进T2I生成的方法。
这个问题并不是一个全新的问题,因为在深度学习时代,T2I生成模型已经经历了多次迭代和进化,包括生成对抗网络(GANs)、变分自编码器(VAEs)和扩散模型(DMs)。
不过,本文提出的解决方案是新颖的,因为它引入了丰富的人类反馈来改善评估和生成过程,这是对现有方法的扩展。
关键
丰富的人类反馈:通过标记图像中的不合理或与文本不一致的区域,并注释文本提示中未正确表示或缺失的词汇,收集更细致和可解释的反馈。
**多模态Transformer**:设计了一个名为RAHF的模型,用于自动预测丰富的人类注释。
预测的反馈的下游应用:使用预测的反馈来改善图像生成过程,包括选择高质量的训练数据进行微调,以及创建掩码来修复问题区域。
方法
构建了一个数据集
论文收集了18,000张生成图像的丰富人类反馈,包括点注释、文本标记和细粒度评分。注释数据的要点详见图一,注释者在图像上标记点以指示与文本提示相关的不合理区域(图中红点,如熊猫的鼻子和轮毂部分)或图文不一致区域(图中蓝点,如右侧熊猫)。然后,标注者点击单词以标记不匹配的关键词(右侧下划线和着色文字,例如这里有两只熊猫),并为可信度、图文对齐程度、美观度和整体质量选择分数(右侧下划线文字)。

模型训练

注意看他的输出,是自动预测丰富的人类注释
这篇论文到底有什么贡献?
- 数据集创建:首次创建了一个包含18,000张图像的丰富人类反馈数据集(RichHF-18K),它包括对图像中不合理或与文本描述不一致区域的标注、文本中缺失或错误表示的关键词的标注,以及对图像的合理性、文本-图像对齐、审美和整体质量的细粒度评分。
- 模型设计:提出了一个多模态变换器模型RAHF,该模型能够自动预测人类对生成图像的丰富反馈。这包括对不合理区域和文本-图像不一致区域的热图预测,以及对图像质量的细粒度评分预测。
- 提高生成质量:展示了如何利用RAHF模型预测的丰富人类反馈来改善图像生成过程。具体方法包括使用预测的热图作为掩码进行问题区域的修复,以及使用预测的评分来指导生成模型的微调,从而提高生成图像的质量。
- 泛化能力证明:证明了通过RAHF模型获得的改进不仅可以应用于生成训练数据集中的模型(如Stable Diffusion变体),还可以推广到其他模型(如Muse),显示了RAHF模型良好的泛化能力。
下一步呢?有什么工作可以继续深入?
- 提高标注质量:论文提到了在标注过程中存在的一些问题,如对人类面部和手部的过度标注。未来的工作可以探索改进标注指南和流程,以减少此类问题。
- 探索新的应用场景:RAHF模型目前主要应用于图像生成的评估和改进。未来的研究可以探索将该模型应用于其他领域,如图像编辑、视频生成或虚拟现实内容创建。
- 集成到生成模型中:将RAHF模型集成到T2I生成模型的训练过程中,可能通过直接使用预测的反馈作为训练信号来提高生成质量。
- 奖励信号的进一步研究:使用预测的反馈作为强化学习的奖励信号,以微调或训练生成模型,这可能是一个值得探索的方向。
- 伦理和社会影响研究:随着T2I技术的发展,研究其对社会、文化和伦理的潜在影响,确保技术的健康发展和使用。