AlexNet
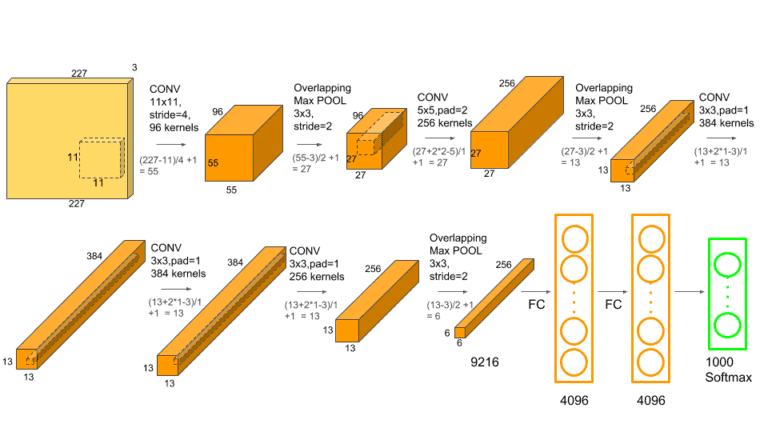
AlexNet
JJuprising9年后重读深度学习奠基作之一:AlexNet【论文精读·2】_哔哩哔哩_bilibili
读论文
- 第一遍:题目摘要讨论总结,一些图和公式
BERT无监督
AlexNet之前事无监督,AlexNet有监督
把最后一层的输出向量拿出来对比,在语义空间表示很好
写论文最好不要局限小领域小方向,其他的也要提提公平些。
研究能够让别人往下做是比较好的,而不是纯堆技术做的非常强。
end-to-end端到端,原始图片文本进去,神经网络直接做出来
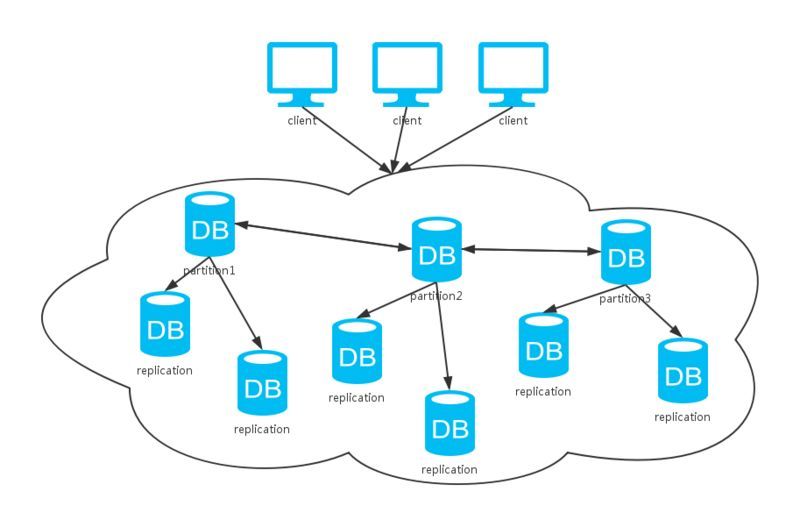
结构图,维度是输入输出数据大小,中间小块是卷积核
维度长宽逐渐降低降低,一小块表征原始的一大块,而通道不断增加,语义上信息的理解,这个通道理解猫腿,这个理解一个边等
不断压缩,增加语义理解
drop out 正则的东西
sgd机器学习应用广泛的优化算法。weight decay加在模型上,其实就是一个L2正则化
利用均值为0,方差为0.01的高斯分布初始化权重,以后的工作全部初始化为0也不错。BERT是方差为0.02,和模型复杂度有关。
现在用平滑曲线来下降学习率,比如一个cos函数,横坐标是epoch。AlexNet就是每次下降10倍,节点手动选择。