大数据原理与实践

大数据原理与实践
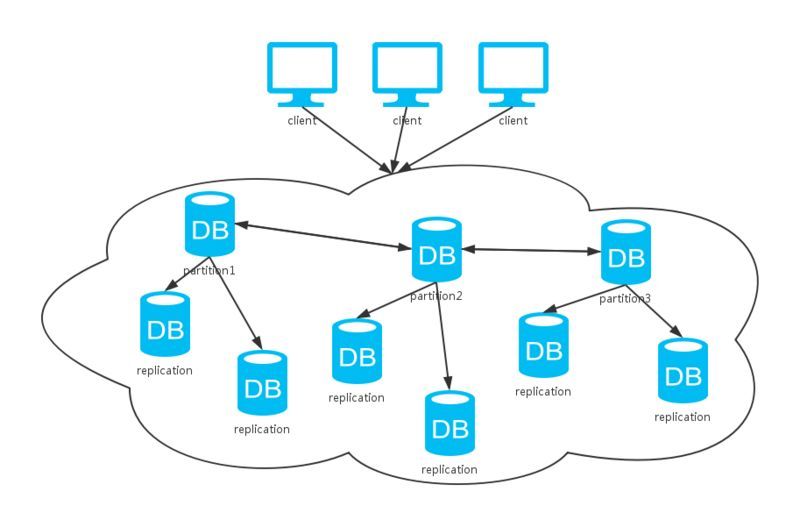
JJuprising12为了能够管理多台分布式系统,出现了HDFS
Hadoop是一个分布式系统架构
程序员如何编写程序管理,出现了MapReduce,提供了并行框架,map切分,Reduce就是汇总阶段
如何在Hadoop上写SQL,于是出现了Hive,它是一个进行结构化数据处理的解决方案,为了能让用户使用SQL处理数据,S就是结构化。Hive将SQL翻译成MapReduce。
Spark被用来和Hadoop的MapReduce对比。MapReduce是基于磁盘的计算框架,而Spark是基于内存,主打的快。同理也有Spark on SQL
Hadoop基础
MapReduce并行计算架构
YARN
HDFS分布式文件系统
HDFS
计算机集群
- 将文件分布存储到多个计算机节点,节点构成计算机集群
- 计算机集群都是由普通硬件构成,大大降低硬件开销
- 通过“心跳”判断是否节点损坏,有多个副本,不怕损坏
结构
- 采用主从结构,有主节点和从节点
- 一个主节点关联多个从节点,一个从节点关联多个主节点,因此数据在不同从节点中有多个副本
Block-块
- windows块大小是4k,而HDFS默认默认一个块128MB,一个文件被分成多个快,以块为存储单位
- 块大也可以最小化寻址开销
- 抽象块概念好处
- 支持大规模数据存储
- 简化系统设计
- 适合数据备份
HBase
和传统关系数据库的对比
HBase行操作,处理大型数据会方便
(1)数据类型:关系数据库采用关系模型,具有丰富的数据类型和存储方式;HBase采用简单的数据模型,把数据存储为未经解释的字符串
(2)数据操作:关系数据库包含丰富的操作,涉及复杂的多表连接。HBase不存在复杂的表与表之间的关系,只有简单的插入、查询、删除、清空;HBase在设计上避免复杂的表和表之间的关系
(3)存储模式:关系数据库:基于行模式存储。
(4)数据索引:关系数据库:可以针对不同列构建复杂的多个索引,以提高数据访问性能;
HBase只有一个行键索引,通过巧妙的设计,HBase中的所有访问方法,或者通过行键访问,或者通过行键扫描,从而使得整个系统不会慢下来
(5)数据维护:关系数据库:更新操作会用最新的当前值去替换记录中原来的旧值,旧值被覆盖后不会存在。
HBase中执行更新操作时,不会删除旧版本,而是生成一个新的版本
(6)可伸缩性:关系数据库很难实现横向扩展,纵向扩展的空间也比较有限。
HBase能轻易地通过在集群中增加或者减少硬件数量来实现性能的伸缩
数据模型
行:每个HBase表都由若干个行组成,每个行由行键标识
列族:列族数据通过列限定符来定位
单元格:行和列确定的

功能组件
两个组件
- 一个Master主服务器,负责管理
- 多个Region服务器,负责维护和分配给自己的Region
一个HBase表被划分成多个Region,一个Region会分类为多个新的Region


Region 的定位
元数据表META表,存储REgion和Region服务器映射关系
当HBase表很大,META表会分裂多个Region
根数据表,又名-ROOT-表,记录所有元数据的具体位置
-ROOT-表只有唯一一个Region
Zookeeper文件记录了-ROOT-表的位置

内存大数据计算架构Spark
- 快速、通用的开源大数据处理引擎
- 与Hadoop平台类似,兼容
Spark RDD
特性:
- 数据集合
- 弹性分布
- 可持久化
- 分布式存储
- 只读
- 可重新计算
RDD转换操作
| RDD****转换 | 含义 |
|---|---|
| map(func) | 通过函数func对数据集中的每个成员进行转换 |
| filter(func) | 通过函数func选择过滤数据集中的成员 |
| flatMap(func) | 和map转换类似,但函数func可以把单个成员转换为多个成员。 |
| union(other) | 返回当前集合与otherDataset集合的union操作 |
| distinct | 去掉集合中重复成员,使新的集合中成员各不相同 |
| groupByKey | 对键-值(key-value)对集合按照键(key)进行groupBy操作 |
| sortByKey | 对键-值(key-value)对集合进行排序 |
| join(other) | 对两个键-值(key-value)对集合:(K,V),(K,W)进行连接操作,形成新的键-值对集合:(K,(V,W)) |
RDD依赖关系:RDD转换生成新的RDD, 新的RDD依赖于旧的形成依赖关系
窄依赖:map rdd1一个只对一个rdd2
宽依赖:一个对多个