Deep Learning

Deep Learning
JJuprising基础知识
机器学习
机器学习三大范式
- 监督学习,数据+标签
- 无监督学习,大数据没法给标签,根据相似性将用户自动分成几类
- 同一类人群,产品可以互推
- 强化学习
- 扫地机器人,撞到扣分,没撞到加分
K邻近
聚类算法
- 簇的个数是超参数,假设是3
- 随机选三个中心点,计算中心点和其他点的距离,求平均距离
- 改变中心点,如果距离要小,说明更合适作为中心点
- 中心点改变有多种策略
如何选取簇,对于多维,两两选择特征画图,多画几个看能分成几个簇,然后直接选最大的那个
如果在报告里,就做主成分分析,找出最具代表性的特征,两两组合判断簇个数,然后开始聚类
随机初始化选簇,然后进行聚类计算。目的就是逐渐逼近一个最优解
聚类算法
- DBSCAN,在skilearn里有开源代码
- AP邻近传播算法
逻辑回归
这里就要提到sigmoid函数。比如,预测会不会下雨,样本标签只有会(1)和不会(0),这种情况没办法用线性方差拟合。而sigmoid就可以拟合这个关系。假设横轴是云雾密度,那么我们可以更具x轴得到一个预测值,如果大于0.5就预测为会下雨,小于0.5预测不会下雨
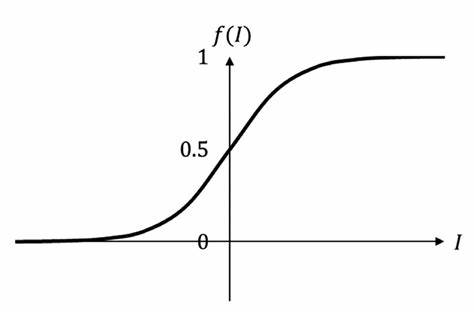
逻辑回归(logistic regression)就是对于我们f(z)=sigmoid(z)=1/(1+ez),z本身是一个函数z=wx+b,这是f(z)就是一个逻辑回归函数
决策边界:就是将两种类型的样本划分的边界,先观察,再确定,例如直线/椭圆
线性回归
代价函数
$$
J(\vec{w},b)=\frac{1}{m}\sum_{i=1}^{m}\frac{1}{2}(f_{\vec{w},b}\big(\vec{x}^{(i)}\big)-y^{(i)})^{2}
$$
对于线性回归,一般是凸代价函数,在梯度下降中就能够一步一步逼近全局最优,然而逻辑回归的非凸代价函数就容易陷入局部最小值。上面的代价函数,求和里边代表单个训练样本。我们在计算损失时就是用的里面单个训练样本来计算。
因此我们需要选择合适的损失函数,使得总的代价函数是一个凸函数
逻辑损失函数
为什么要这样定义损失函数,我们根据图来分析
$$
L\big(f_{\vec{w},b}\big(\vec{x}^{(i)}\big),y^{(i)}\big)=\begin{cases}-\log\Big(f_{\vec{w},b}\big(\vec{x}^{(i)}\big)\Big)&\text{if}y^{(i)}=1\-\log\Big(1-f_{\vec{w},b}\big(\vec{x}^{(i)}\big)\Big)&\text{if}y^{(i)}=0\end{cases}
$$
核心点就是,当预测值越接近实际值,则loss越小奖励越大
当越远离,则loss越带,需要惩罚
参考下图,对于y标签为1的样本,我们看-log的蓝色,因为y取值只有0-1,所以直接看左边。(图例的1/3看作1)当x越接近1,对应的y越小,loss越小
同理,-log(1-x)也就是当x越接近0,损失越小

可以证明,当用这样一组loss去优化上面的总代价函数就是一个凸函数,能够逐步得到全局最优解。
梯度下降
尽管两个的损失函数是一样的,但是f函数的定义不一样,logistic定义是sigmoid

加快梯度下降的方法(和线性回归相似)
- 观察学习曲线
- 矢量化
- 特征缩放(如投影到-1,1)
如何理解
例如对于下面的损失函数:
$$
w=w-α×\frac{\partial J(w)}{\partial w}
$$
我们假设J(w)函数图像(学习率下面),可以看到后面的微分就是在w点处的导数即斜率,当斜率为正数,w=w-α×正数,w变小;斜率为负数,w=w-α×负数,w变大。可以看到,w都在朝着代价函数J(w)不断减小的方向进行。α指的是学习率
学习率
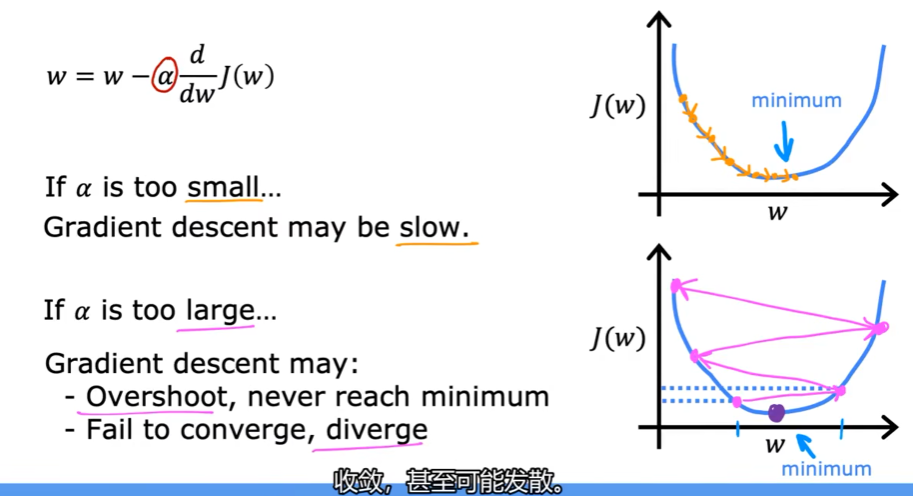
可以看到,学习率比较小的时候,梯度下降会很慢;当学习率很大的时候,可能收敛不了
局部最小值问题
当损失函数处于最小值,根据公式此时导数项为0,w=w,不会再更新了,陷入局部最小值
当函数是一凸函数,例如线性回归,他的损失函数是一个碗形,也就是只有一个全局最小值,那么梯度下降就可以找到最小值
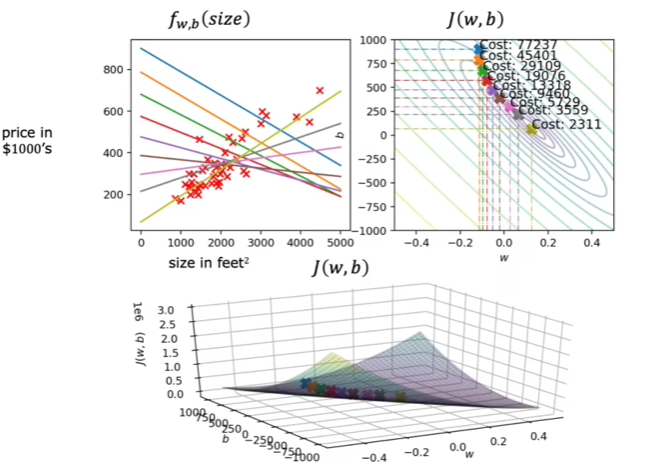
从上图可以看到,当点的越接近最小值,左上角的直线能够更好拟合数据
批梯度下降
多维线性回归
多元特征
一位特征:f(x)=wx+b
多维特征:f(x)=w1x1+w2x2+w3x3+w4x4+b
把x和w表示为向量,即W=[w1,w1,…,wn],X=[x1,x2,…,xn]
f(x)=W·X+b,·向量点积,这个算法叫多元线性回归。
矢量化 vectorization
在python的numpy中:
1 | w=np.array([1.0,2.5,-3.3]) |
多层感知机
激活函数
损失函数
梯度下降
什么是梯度下降
作用:优化损失函数
找极小值(损失函数要找最小)
梯度:梯度就是函数对它的各个自变量求偏导后,由偏导数组成的一个向量。简单来说就是导数多了方向(这个很关键,后面提到)
在下图情况有可能陷入局部最小值,也就是左边最小值,但他不是全局最小
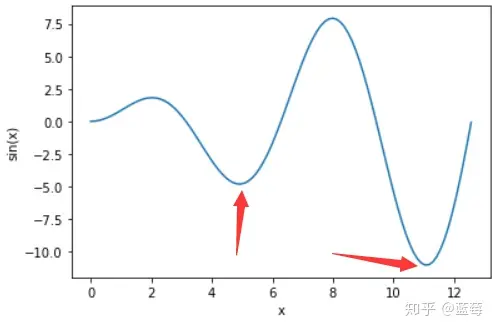
因此,就需要随机初始化几次,多尝试几次
那么如何找呢,以一元二次函数f(x)=(x-1)^2+1为例
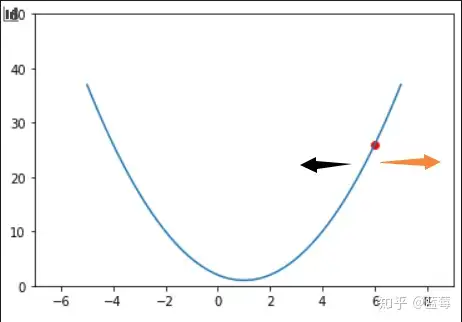
假设红点处是一个初始值,我们对该点进行求导,导函数fx=2x-2,当x减小,也就是黑色箭头方向,导数是在减小的,代表导数反方向;橙色箭头方向,导数增加,代表导数正向。
为了找到极小值,我们需要让红点x朝着黑色方向移动,这就是梯度下降的目的。实现这一过程,需要提到学习率eta
$$
x\leftarrow x-eta*\frac{df(x)}{dx}
$$
让x减去学习率eta乘以函数的导数。学习率eta的目的是控制x更新的幅度,如果eta小,那么x每次更新的幅度就小
进行迭代更新,曲线逐渐平缓,最终会收敛到一个局部的极值点,也就是当导数无限逼近0,最终停留在极值点。
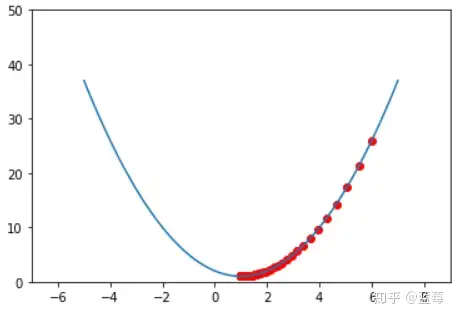
神经网络与梯度下降
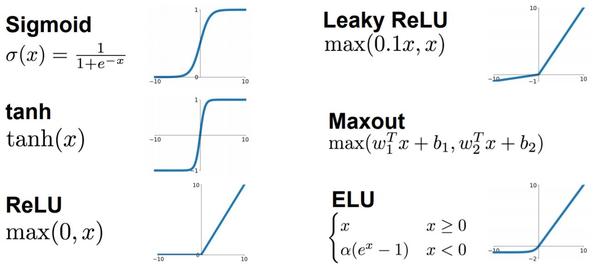
神经网络方面的一个巨大突破是从 sigmoid 函数转换到一个 ReLU 函数,Rectified Linear Unit
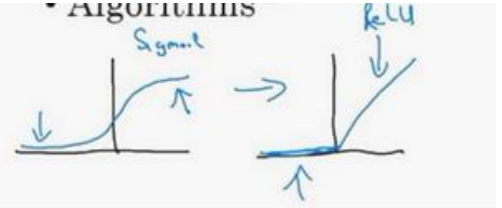
为什么?
使用sigmoid,在x轴负向,梯度会接近0,学习速度变得很慢
而换用ReLU,对于输入的负值,梯度都是0,不会趋向逐渐减少到0,这使得梯度下降算法运行得更快。
超参数
学习率
学习率决定了在每步参数更新中,模型参数有多大程度(或多快、多大步长)的调整
学习率是在梯度下降的过程中更新权重时的超参数,即下面公式中的eta
$$
x\leftarrow x-eta*\frac{df(x)}{dx}
$$
学习率越低,损失函数的变化速度就越慢,容易过拟合。虽然使用低学习率可以确保我们不会错过任何局部极小值,但也意味着我们将花费更长的时间来进行收敛,特别是在被困在局部最优点的时候。而学习率过高容易发生梯度爆炸,loss振动幅度较大,模型难以收敛。
学习率的影响:
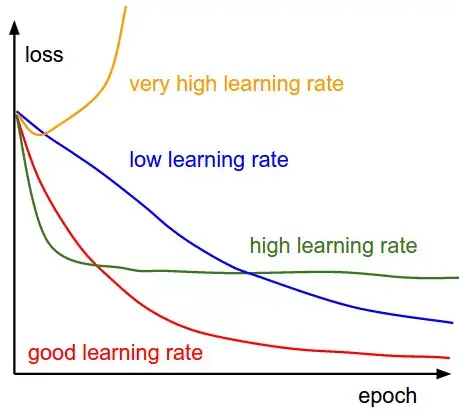
如何设置和调整学习率
调整学习率的套路通常是:
- 先设置一个初始学习率。这个初始学习率应该让损失尽可能快地降低。
- 然后训练过程中按照一定的schedule降低学习率;或用算法根据实际训练情况,自适应地调整学习率。
另外,在正式开始训练之前, 还应该有一小段热身的过程。热身的原因是一开始模型参数是完全随机的,需要谨慎地更新参数,不能一上来就用初始学习率。
优化器
SGD(随机梯度下降)
基本思想: SGD在每一步更新中仅使用一个(或一小批)样本来计算梯度,而不是使用整个数据集。这种方法可以显著减少计算量,使得训练大规模数据集变得可行。
学习率: SGD通常需要手动调整学习率,并且可能会使用如学习率衰减这样的技巧来帮助模型收敛。学习率的选择对SGD的性能影响很大。
收敛速度: SGD的收敛速度通常比较慢,尤其是在接近最小值的平坦区域。
泛化能力: 研究表明,由于SGD的噪声更大,它可能有助于模型找到泛化性能更好的解。
Adam(自适应矩估计)
基本思想: Adam是一种自适应学习率的优化算法,它结合了动量(Momentum)和RMSprop的优点。Adam会为不同的参数计算不同的自适应学习率。
学习率: Adam自动调整学习率,通常不需要像SGD那样手动微调学习率,这使得Adam在很多情况下都能较快地收敛。
收敛速度: 由于自适应学习率的特性,Adam在初期训练阶段通常比SGD收敛得更快。
泛化能力: 尽管Adam在许多任务中都显示出了较快的收敛速度,但一些研究表明,对于某些问题,Adam可能导致过拟合,泛化能力不如SGD。
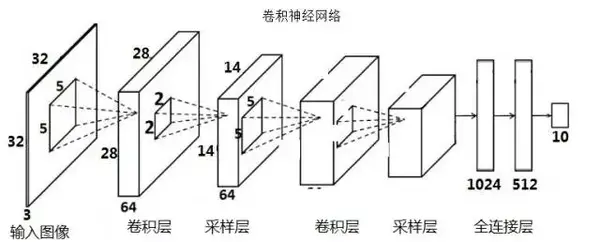
卷积神经网络
简单神经网络和卷积神经网络
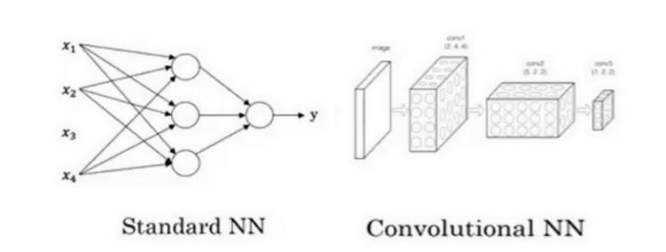
卷积神经网络起到一个分类器的作用
卷积层负责提取特征,采样层负责特征选择,全连接层负责分类
卷积
卷积层如何提取特征呢?
用到卷积核又叫滤波器,(convolution kernel)是可以用来提取特征的
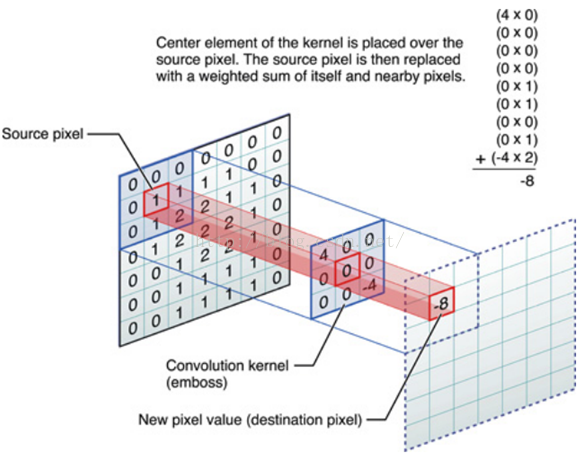
卷积核放在神经网络里,就代表对应的权重(weight)
卷积核和图像进行点乘(dot product), 就代表卷积核里的权重单独对相应位置的Pixel进行作用
至于为什么要把点乘完所有结果加起来,实际上就是把所有作用效果叠加起来
我们知道输入,知道神经元的权值(weights)了,根据神经网络公式:
$$
\sum_iw_ix_i+b
$$
还需要设置偏置bias,先假设为0
我们分别对三个分量的其中一个3x3的九宫格进行卷积
所以,结果为:
W1output = 1*(-1) +11+10+0*(-1)+10+21+0*(-1)+11+2(-1) =1
W2output = 21+20+11+11+01+02+01+00+1*1=5
W3output = 1*(-1)+1*(-1)+0*(-1)+02+0(1)+02+10+11+01 = -1
Bias = 0
Final_output =W1output + W2output+W3output+bias= 1+5-1+0 = 5
三个卷积核的输出为什么要叠加在一起呢
你可以理解为三个颜色特征分量叠加成RGB特征分量
但是,不能够对pixels随即找然后进行卷积,除了特征值,还有相对位置需要考虑。
因此,也需要按照正确的顺序去进行卷积。
最经典的就是从左到右,每隔x列Pixel,向右移动一次卷积核进行卷积(x可以自己定义)
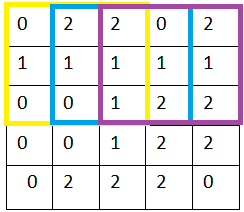
到达最右。从上到下,每隔y行pixel,向下移动一次卷积核,移动完成,再继续如上所述,从左到右进行
就这样,我们先从左到右,再从上到下,直到所有pixels都被卷积核过了一遍,完成输入图片的第一层卷积层的特征提取
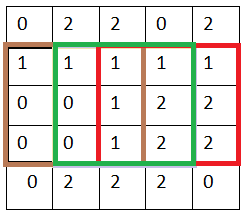
这里的x我们叫作stride,就是步长的意思,如果我们x = 2, 就是相当每隔两行或者两列进行卷积
同时我们可以看到,分量的pixel 外面还围了一圈0,称为补0(相当于什么信息都没加)。对比补了0和没补0,同样一行,补0执行了多几次的卷积操作,好处在于:
可以获得更多细致特征信息,比如图像的边缘信息
我们可以控制卷积层输出的特征图的size,从而可以达到控制网络结构的作用,还是以上面的例子,如果没有做zero-padding以及第二层卷积层的卷积核仍然是3x3, 那么第二层卷积层输出的特征图就是1x1,CNN的特征提取就这么结束了。
同样的情况下加了zero-padding的第二层卷积层输出特征图仍然为5x5,这样我们可以再增加一层卷积层提取更深层次的特征
卷积神经网络(CNN)入门讲解 - 知乎 (zhihu.com)
涉及到具体代码,如何变化举例
1 |
|
conv1 层是一个二维卷积层。我们来详细解释一下 conv1 的参数以及它是如何改变输入张量的维度的。
conv1 参数
in_channels=1:输入的通道数是 1。out_channels=16:输出的通道数是 16。kernel_size=(15, 16):卷积核的大小是 15x16。stride=(15, 16):步幅是 15(在高度方向)和 16(在宽度方向)。bias=False:没有偏置项。
输入形状
- 输入形状是
[batch_size, 1, seq_len, d_model],即[64, 1, 125, 128]。
卷积计算
卷积层的输出维度计算如下:
输出高度 (Output Height)
公式:
$$
\text{output_height} = \left\lfloor \frac{\text{input_height} - \text{kernel_height}}{\text{stride_height}} \right\rfloor + 1
$$
在我们的例子中:
$$
\text{output_height} = \left\lfloor \frac{125 - 15}{15} \right\rfloor + 1 = \left\lfloor \frac{110}{15} \right\rfloor + 1 = 7 + 1 = 8
$$
输出宽度 (Output Width)
公式:
$$
\text{output_width} = \left\lfloor \frac{\text{input_width} - \text{kernel_width}}{\text{stride_width}} \right\rfloor + 1
$$
在我们的例子中:
$$
\text{output_width} = \left\lfloor \frac{128 - 16}{16} \right\rfloor + 1 = \left\lfloor \frac{112}{16} \right\rfloor + 1 = 7 + 1 = 8
$$
输出形状
- 通道数变为
out_channels,即 16。 - 高度变为
output_height,即 8。 - 宽度变为
output_width,即 8。
所以卷积层 conv1 的输出形状是 [batch_size, out_channels, output_height, output_width],即 [64, 16, 8, 8]。
总结
具体维度变化如下:
输入形状:
- 输入张量
x的形状是[batch_size, seq_len, d_model],即[64, 125, 128]。
- 输入张量
扩展维度:
x.unsqueeze(1)将输入形状扩展为[batch_size, 1, seq_len, d_model],即[64, 1, 125, 128]。
卷积层:
self.conv1(x.unsqueeze(1))将输入形状[64, 1, 125, 128]变为[64, 16, 8, 8]。
因此,通过 conv1 层,数据维度从 [64, 1, 125, 128] 变为 [64, 16, 8, 8]。
采样层(池化层,pooling)
最大池化
最大池化Maxpooling字面意思就是,直接取最大的
例如下面矩阵图,数值代表特征程度
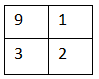
最大池化选择9,含义就是9代表这个区域,最符合特征的,然后去掉没有的。
为什么要这么做?作者举了个很形象的例子
比如这里四个美女要选一个,每个人的选择都是最符合自己的(也就是四个中最符合的特征),其他的丢掉

那为什么不能都选呢?——不做Maxpooling
首先你娶回4个,她们会各种勾心斗角,让你崩溃(overfitting)
然后你会有巨大的经济压力,身体也吃不消(参数过多导致运算量大)
最后可能还会难以平衡婆(上一次卷积层)媳或者母子(下一层卷积层)关系(无法满足模型结构需求)
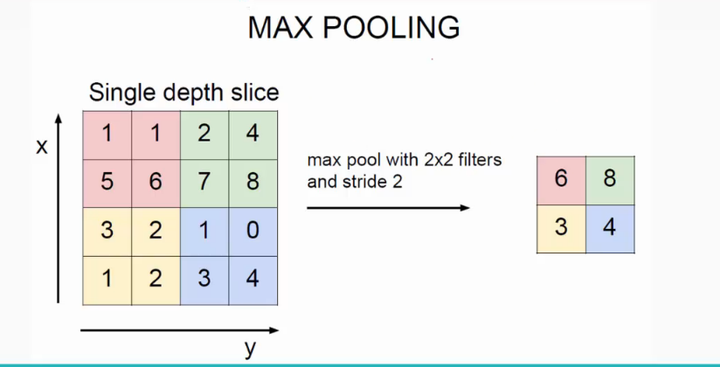
如何进行
例如下图 ,可以类比卷积,就是一个2X2的卷积核,stride为2,从左到右从上到下,作用是选取核里最大的值,而不是做卷积运算
池化的性质
可以一定程度提高空间不变性,比如说平移不变性,尺度不变性,形变不变性
空间不变性体现在,卷积是对一个区域一个区域进行卷积,CNN关注单独区域的特征以及特征之间的相对位置。
当图像发生细微变化,经过卷积和maxpooling,输出结果和原来差别可能不大甚至很小
平移不变性:图像经过一个小小的平移之后,依然产生相同的池化特征
激活函数
在接触到深度学习(Deep Learning)后,特别是神经网络中,我们会发现在每一层的神经网络输出后都会使用一个函数(比如sigmoid,tanh,Relu等等)对结果进行运算,这个函数就是激活函数(Activation Function)。
为什么要激活函数?简而言之因为神经网络每层输入输出都是线性求和过程,不管怎么叠加变换,都是线性组合不能解决非线性问题。而通过激活函数可以使神经网络逼近任何非线性函数,应用于复杂的非线性分类问题
我们从最简单的开始讲
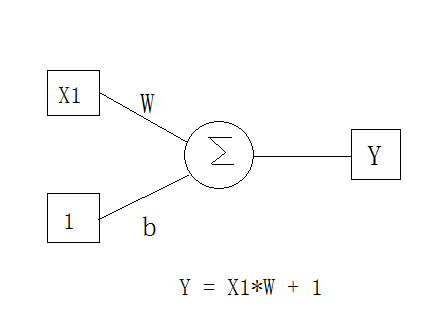
线性方程
下图就是一个最简单的神经元,Y=W*X1+1,其实就是一个线性方程
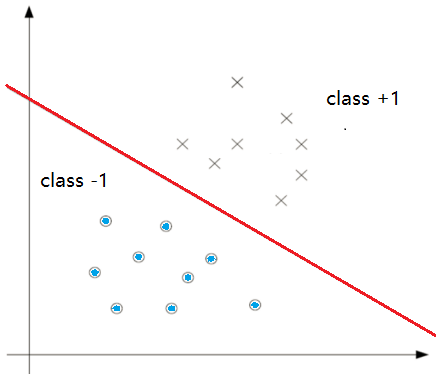
然而,这个神经网络只能够解决普通的线性二分类问题,比如
现实中,其实更多的都是复杂的二分类,具有非线性的特点。那么怎么做呢?
首先叠加神经网络行不行?这里我们对神经元进行叠加,列出公式
Output = w7(input1w1 +input2w2)+w8(input1w3+input2w4)+w9(input1w5+input2w6)
Output = input1(w1w7+w3w8+w9w5)+input2(w2w7+w4w8+w6*w9)
我们假设Output = 0
那么input1 = input2*( w2w7+w4w8+w6w9)/(-w2w7+w4w8+w6w9)
这又回到了一个线性方程。由于线性函数具有可加性和其次性,所以仅靠简单的叠加是不能够解决非线性问题的。
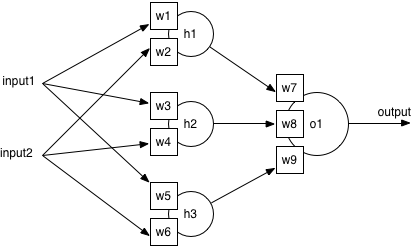
待解决问题
非线性
那如何将线性神经网络转为非线性呢?我们首先想到二次函数y=wx2+B
某一个二次函数经过调整,可以将非线性问题进行分类:
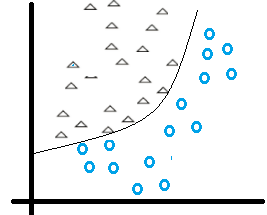
输出需要进行分类
我们的神经网络(还是最简单的)
Y =W*X +B
根据input X的值,我们会得到Y值
所以我们需要一个函数可以对得到的Y值进行分类的
比如Y大于0 ,分类为1
小于0 ,分类为0
输入可能特别大
对于神经网络Y=W*X+B,我们需要算出输出误差error (output Y - target Y) 来更新权值
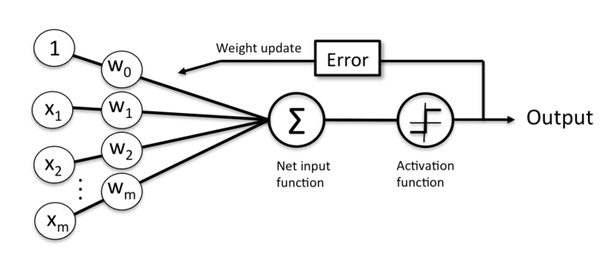
如果输出X绝对值太大甚至无限大,那么输出Y会特别大,直接导致Error非常大,那么更新出来的权值没有意义或无法更新权值
线性方程梯度与输入无关了
线性神经网络导数为常数,那么梯度gradient就与输入X无关了
在反向传播时候,梯度改变也变为常数,和输入的改变关联不上了
激活函数
解决上面的问题,就需要激活函数了
dropout
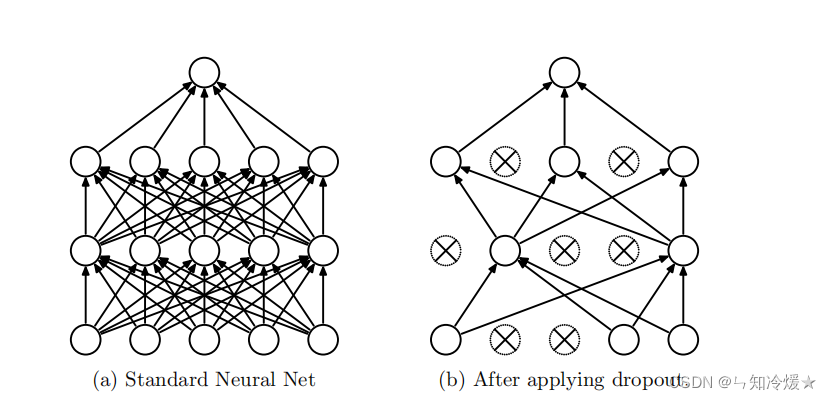
为什么需要dropout:采样一个更薄的神经网络,减少神经元之间的共适应性,迫使学习更加鲁棒 的特征
产生DropOut的动机:使用DropOut训练的神经网络中的每个隐藏单元必须学会与随机选择的其他单元样本一起工作,这样会使得每个隐藏单元更加的健壮,并使得他们尽量自己可以创造有用的功能,而不是依赖其他隐藏单元。即按照论文的话来说:减少神经元之间复杂的共适应关系。
官方论文例子: 50个人,分十个组,每五个人完成一个小阴谋,可能比50个人正确扮演各自角色完成一个大的阴谋更容易,当然,在时间足够,各种条件没有改变的情况下,那么完成一个大阴谋是更适合的,但生活总是充满变数,大阴谋往往不太容易实现,这样小的阴谋发挥作用的机会就会更大。同样的,在训练集上,各个隐藏单元可以协同发挥作用,即可以在训练集上可以训练的很好,但是这并不是我们需要的,我们需要他们在新的测试集上可以很好的合作,这时候DropOut体现出了它的价值!
本质上看: DropOut通过使其它隐藏层神经网络单元不可靠从而阻止了共适应的发生。因此,一个隐藏层神经元不能依赖其它特定神经元去纠正其错误。因为dropout程序导致两个神经元不一定每次都在一个dropout网络中出现。这样权值的更新不再依赖于有固定关系的隐含节点的共同作用,阻止了某些特征仅仅在其它特定特征下才有效果的情况 。迫使网络去学习更加鲁棒的特征 ,这些特征在其它的神经元的随机子集中也存在。
https://blog.csdn.net/weixin_42475060/article/details/128862411
全连接层
全连接层的作用主要就是实现分类(Classification)
训练完到最后一步:
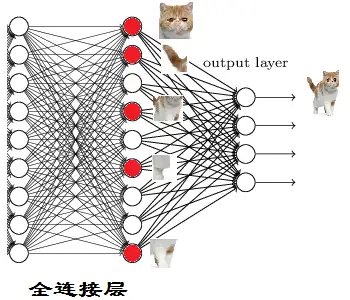
猫头猫尾…–>猫
再往前可以做对子特征进行分类:
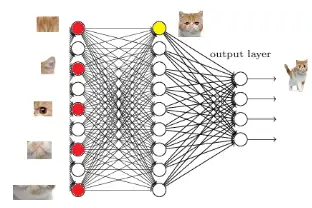
猫眼猫胡须…–>猫头
这些细节特征哪来的呢?就是从前面的卷积层,下采样层来的。
二层全连接
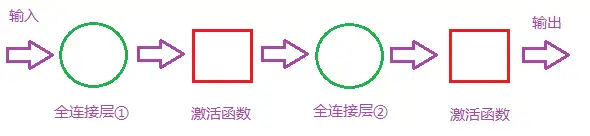
全连接层对模型的影响因素:
- 全连接层的总层数(长度)
- 单个全连接层的神经元数(宽度)
- 激活函数(作用:增加模型的非线性表达能力)
如果全连接层宽度不变,增加长度(总层数):
优点:全连接层数加深,模型非线性表达能力提高。理论上都可以提高模型的学习能力。
如果全连接层长度不变,增加宽度(神经元个数):
优点:神经元个数增加,模型复杂度提升。理论上可以提高模型的学习能力。
难度长度和宽度都是越多越好?
肯定不是
(1)缺点:学习能力太好容易造成过拟合。
(2)缺点:运算时间增加,效率变低。
那么怎么判断模型学习能力如何?看Training Curve 以及 Validation Curve
在其他条件理想的情况下,如果Training Accuracy 高, Validation Accuracy 低,也就是过拟合 了,可以尝试去减少层数或者参数。
如果Training Accuracy 低,说明模型学的不好,可以尝试增加参数或者层数。至于是增加长度和宽度,这个又要根据实际情况来考虑了。
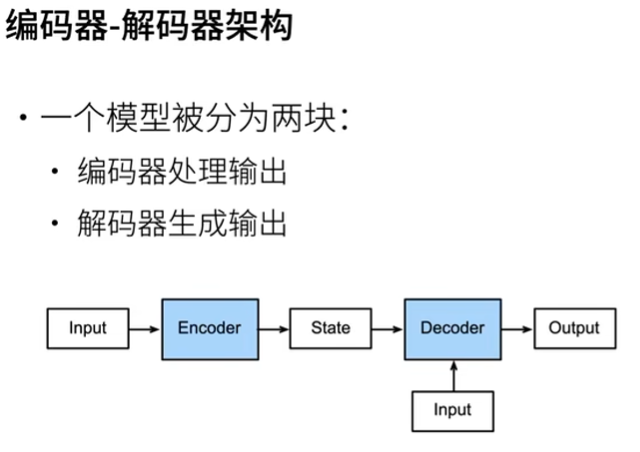
编码器解码器
encoder-decoder
表征学习,数据压缩,特征降维
编码器学习数据的特征,逐步压缩输入信息,目的是将所有必要信息编码到一个抽象的中间表达表示中
解码器的任务是将编码器输出的内部表示转换为目标序列。解码器逐步生成输出序列,每一步都可能依赖于前一步的输出以及从编码器传递过来的上下文信息。在生成过程中,解码器逐渐解开编码器压缩的信息,将其转化为有意义的输出
在这个抽象, 可以给一些随机数,如果模型学习的好,应该能够出来一个和x相近的结果
输入数据要洗牌,从不同角度观察,保证多样性
1 | import torch |
*
深度学习
推荐:
残差网络Resnet
(32 封私信 / 2 条消息) 为什么残差连接的网络结构更容易学习? - 知乎 (zhihu.com)
解决层数增多两个问题:
- 梯度消失或梯度爆炸
- 退化问题
亮点:
- 提出了residual残差结构,超深层数也能训练很好
- 使用batch normalization加速训练(丢弃dropout)

- identity mapping,就是弯弯的线 x
- residual mapping,就是除了弯弯的线 f(x)-x
为什么有效果
在 计算图 中经过了 如下的权重层导致有多条路径可以选择的结果。由于上述计算过程同时设计正向传播和反向传播会贯穿整个网络,导致网络越深,最后的梯度计算结果中前面乘上的权重系数也会越来越多。
结果是前面乘的权重系数会越来越多。因为不管是正向传播还是反向传播,每条路径经过一个权重因子都会乘上这个权重因子。随着层数的增加,路径变得越来越长,在这条路上走一走遇到的权重因子也会越来越多,梯度会整体的变小。
也就是说网络变深了,梯度虽然每层的相同但是整体变小了。如果网络足够深,每一层的梯度都变小到感受不到了。这也就是当初 Hinton 祖师爷虽然用 r e l u relurelu 这个神器解决了梯度分布不均匀的问题,但是却留下了一个更大的问题,权重分布是均匀了但是整体变小了-_-)?
ResNet 的解决方法非常粗暴,就是加入 shortcut 。这个 shortcut 在梯度计算图中相当于增加了一条可以跳过权重的层的路径。使得最终计算所得的权重处的梯度 加上一项 没有经过权重层衰减的梯度。
https://blog.csdn.net/weixin_40267373/article/details/105667134
注意力机制
组件
- Query(查询): 代表需要获取信息的请求。
- Key(键): 与Query相关性的衡量标准。
- Value(值): 包含需要被提取信息的实际数据。
- 权重(Attention Weights): 通过Query和Key的相似度计算得来,决定了从各个Value中提取多少信息
举例说明
假设我们有一个简单的句子:“猫喜欢追逐老鼠”。如果我们要对“喜欢”这个词进行编码,一个简单的方法是只看这个词本身,但这样会忽略它的上下文。“喜欢”的对象是“猫”,而被“喜欢”的是“追逐老鼠”。在这里,“猫”和“追逐老鼠”就是“喜欢”的上下文,而注意力机制能够帮助模型更好地捕获这种上下文关系。
1 | # 使用PyTorch实现简单的点积注意力 |
输出:
1 | 注意力权重: tensor([[0.4761, 0.2678, 0.2561]]) |
这里,“喜欢”通过注意力权重与“猫”和“追逐老鼠”进行了信息的融合,并得到了一个新的编码,从而更准确地捕获了其在句子中的语义信息。
解码注意力Attention机制:从技术解析到PyTorch实战_attention代码pytorch-CSDN博客
Transformer
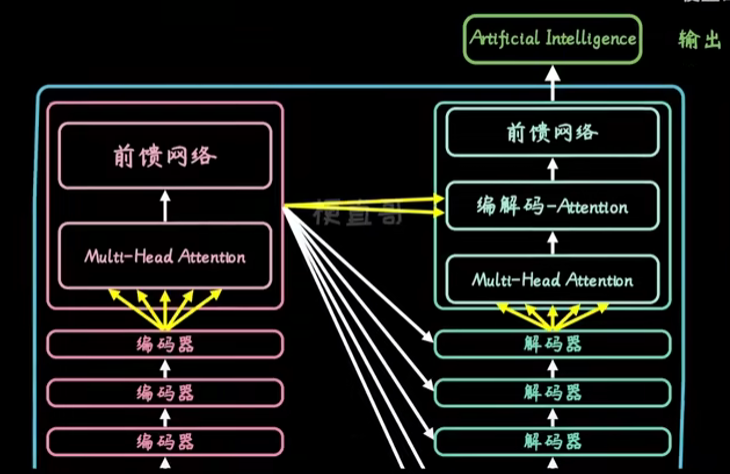
简单来说,tf包含架构就是输入,encoder,decoder,输出
只不过,一般encoder和decoder都会叠很多层
在encoder,包含self attention 和Feed Forward前馈网络,表示将输入赋不同权重关注度后拆解
在decoder,包含self attention, EncoderDecoder-attention和Feed Forward。这里的编解码-attention就是不仅要关注零件本身,还要考虑全局上下文关系。在翻译中,就是不仅要考虑已经翻译的内容,还要考虑上下文意思。
每个self-attention 分解为多个部分,也就是multi-head attention,多头注意力
QKV
https://mp.weixin.qq.com/s/Rn9Ta-V14Ch8j1ORsokDrA

Q,K,V是由输入的词向量x经过线性变换得到的,其中各个矩阵w可以经过学习得到, 这种变换可以提升模型的拟合能力, 得到的Q,K,V 可以理解为Q: 要查询的信息K: 被查询的向量V: 查询得到的值
总结一下:
首先Q、K、V都源于输入特征本身,是根据输入特征产生的向量,但目前我们现在无需关注是如何产生这组向量的。V可以看做表示单个输入特征的向量。当我们直接把一组V输入到网络中进行训练,那这个网络就是没有引入Attention机制的网络。
但如果引入Attention,就需要将这组V分别乘以一组权重α ,那么就可以做到有重点性地关注输入特征,如同人的注意力一般。
关键点
- 自注意力机制
每个字和序列中其他次都有一个权重,来表示关系重要程度,这解决了传统RNN面对长序列会遗忘掉关联信息地问题
- 位置编码
输入数据首先进行词嵌入,即将词用一串数字表示,然后,每个字会有一个位置向量,添加到输入序列中
模型不仅能理解每个词意思,还知道它和上下文的关系,从而理解不同词的顺序
借助位置编码,就可以并行计算(因为已经知道每个词和序列的关系),不像RNN按顺序依次处理文本(训练慢)
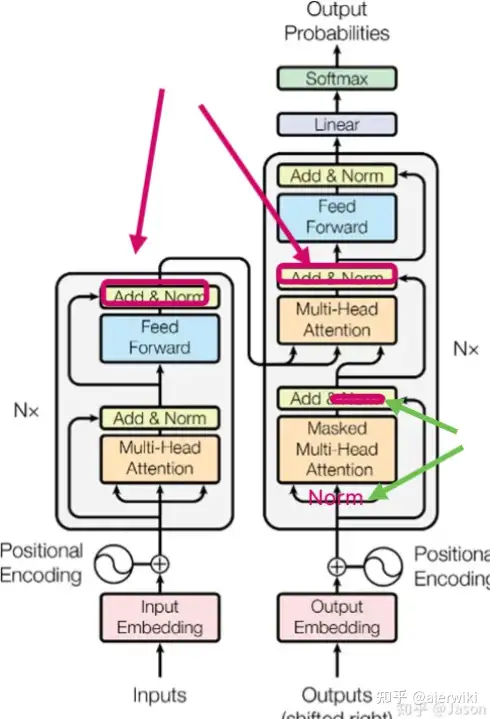
Norm
在transformer中我们可以看到很多Add&Norm操作,也就是说它是先将上一层的输出和当前层的输出相加之后,再进行的LayerNorm,这就属于PostNorm。如果我们像绿色箭头指向的那样,在X输入下一层之前现执行LayerNorm操作,然后传入下一层,同时在下一层只把Xt和Xt+1相加,那就是PreNorm。
也可以作如下总结:
是在Add操作后进行Norm操作,因此叫做Post-Norm。而Pre-Norm则是Norm之后再Add,所以叫Pre-Norm。
迁移学习transfer learning
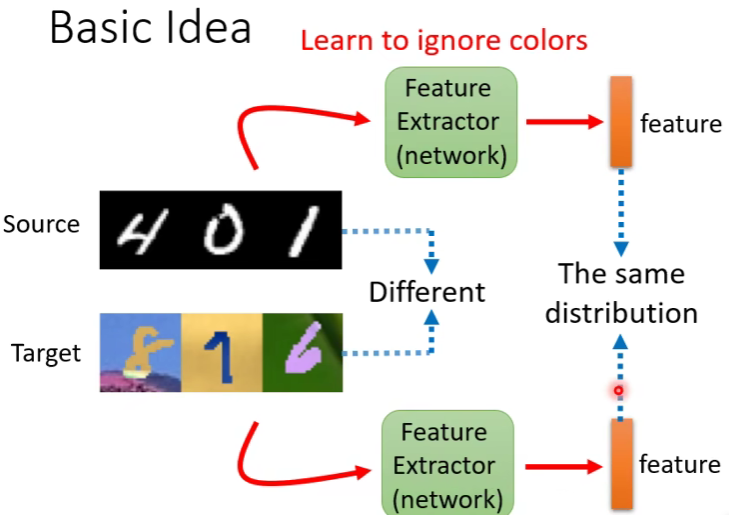
Domain Adaptation
训练集是一个分分布,输入分布与训练是不同的,那么效果会变差很多
例如,训练时黑底白字(源域,source domain),测试是彩色底(目标域, target domain),彩色字
在现实应用中,这种情况非常需要解决,你训练的模型是否能够适应新的分布情况呢
适用环境
目标域有标签的数据很少,那就可以用来回调源域的训练。
- 因为目标域很少,避免overfit,迭代次数不要过多,避免过拟合少数据(学习率 减少)
目标域数据很多,但是没有标注,符合真实场景。下面讲讲这种
Basic idea如图,也就是找一个特征提取器,都提取两个域的特征,然后我们留下共性的部分来用
那么如何找到这个feature extractor呢
域对抗训练 Damain Aversival Trainng
一个基本的模型就是有输入->特征提取->标签预测->输出
不能直接把目标域丢进去,因为就算丢进去出来一个预测标签,因为原始数据中没有label,没有办法判断。
他们的用处就在于,丢进去后,在特征提取器之后拿出来看,我们希望它的feature和源域丢进去得到的feature分不出差异。也就是下图,蓝点和红点差异分不出
因此,问题就来到了如何涉及一个domain classifier。
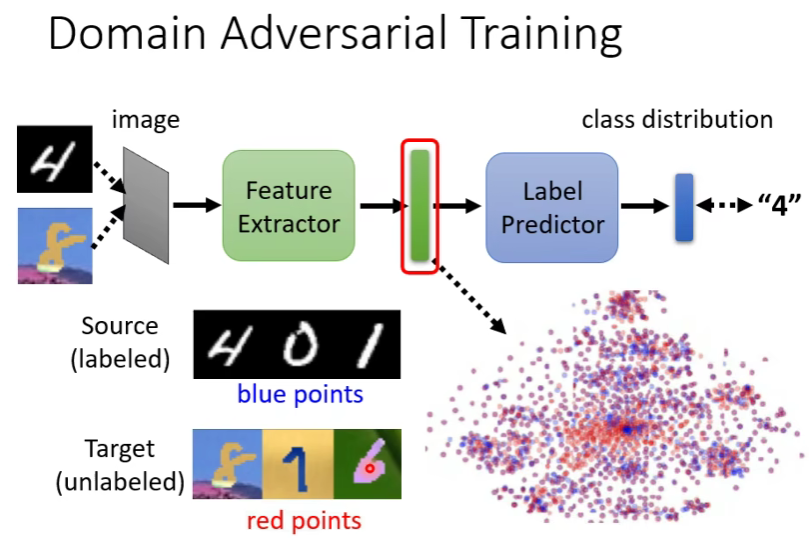
domain classifier是一个二元分类器,他的作用就是判断我们拿到的feature是来自源域还是来自目标域。而feature extractor的任务就是学习如何骗过domain classifier,使得它分不出是来自哪个域的
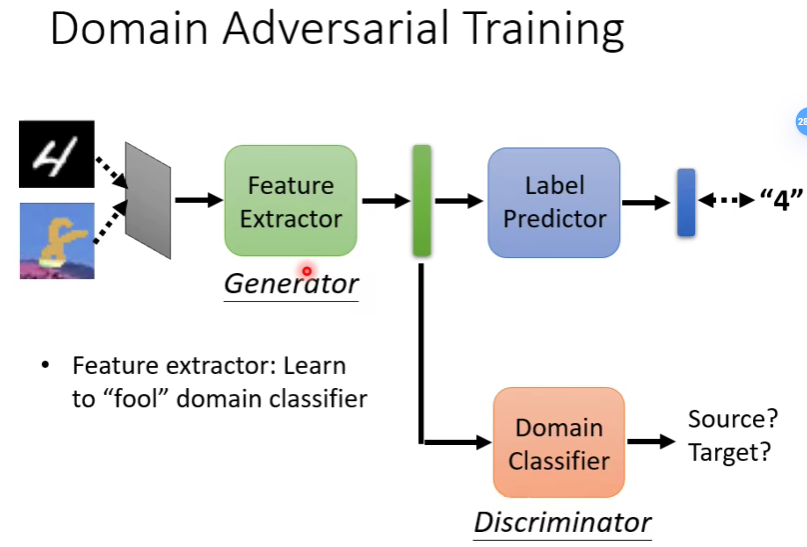
它的结构和GAN很小,可以把feature extractor类比成generator,把domain classifier类比成discriminator
问题来了,如果feature每次都输出一个zero feature不就达到目的了吗
不行的,因为还要让label predictor判断出实际的label,所以不能耍赖。
损失计算
- 在label predictor,因为知道真实标签和域标签,所以可以用cross entropy去算一个loss,记为L
- 在Domain Classifier二元分类,计算Ld,越小越好,越能分出域
- 而Feature Extractor,则是要让L-Ld,越大越好,即能很好分出label,又能够让Domain Classifier分不出。
limitation
- 目标域在boundary分布不同,下图,显然右边效果是我们期望看到的
- 解决办法就是离boundary越远越好,即输出的结果越集中在某个类别(DIRT-T 文献)
- 目标域因为没有标签,他的类别可能会和源域不同(Universal domain adaptation 文章)

DC强行拉直,可能损失latent space信息,并且DC的权重如果过高,LP的效果会很差,因此是不好训练的
当对目标域完全位置的时候,就变成Domain Generalization了。也就是训练是真实的,素描的狗,但是测试的是卡通的狗
又比如训练只有一个domain,测试有多个。这种一般就是先做数据增强(data augmentation),然后就变成上一步的问题
BCI
常见指标
ITR信号传输率
$$
B=log_2{N}+Plog_2{P}+(1-P)log_2[(1-P)/(N-1)]
$$
N为可选目标数,P为目标识别准确率,T为响应时间,
上式B的单位为bit/selection。
ITR值的大小代表了单位时间系统输出的信息量,计算公式如下
$$
ITR=B*C
$$
C表示系统在单位时间内所能做出的决策次数
$$
C=(60/T),T=t_s+t_b
$$
图像生成
自监督学习
自监督学习(self-supervised learning)不需要人工标注的类别标签信息,直接利用数据本身作为监督信息,学习样本数据的特征表达,应用于下游的任务。自监督学习又可以分为对比学习(contrastive learning) 和 生成学习(generative learning) 两条主要的技术路线。
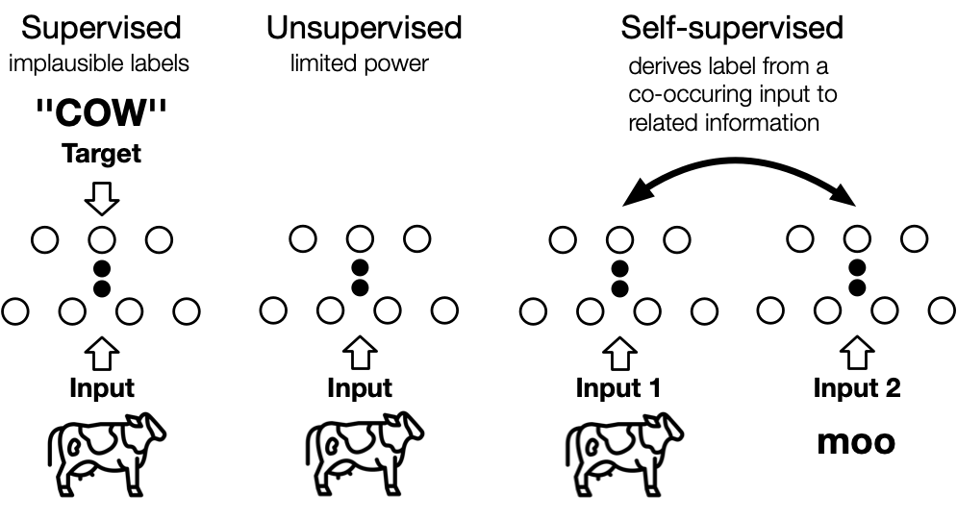
对比学习首先学习未标记数据集上图像的通用表示形式,然后可以使用少量标记图像对其进行微调,以提升在给定任务(例如分类)的性能。
- 简单地说,对比表示学习可以被认为是通过比较学习。
- 相对来说,生成学习(generative learning)是学习某些(伪)标签的映射的判别模型然后重构输入样本。
对比学习
对比学习的核心思想是讲正样本和负样本在特征空间对比,学习样本的特征表示,难点在于如何构造正负样本。

对比学习通过使用三个关键的元素(正样本、anchor、负样本的表征)来实现上述思想。为了创建一个正样本对,我们需要两个相似的样本,而当我们创建一个负样本对时,我们将使用第三个与两个正样本不相似的样本。

CLIP
CLIP的英文全称是Contrastive Language-Image Pre-training,即一种基于对比文本-图像对的预训练模型。
扩散模型
正态分布
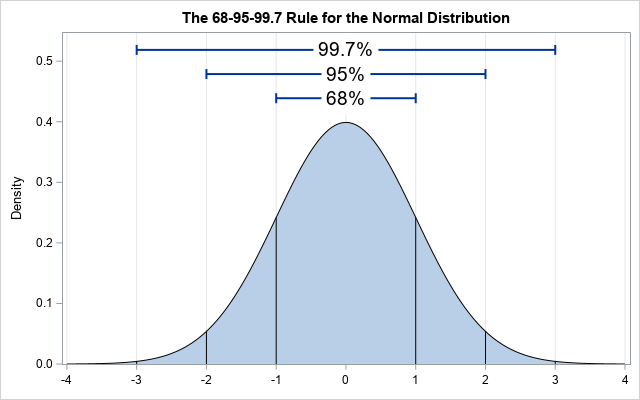
正态分布:如果一个随机事件收很多随机因素影响,但没有任何一个决定性,那么概率分布密度函数就会呈现钟形曲线,即正态分布(高斯分布)
标准正态分布:N(0,12),0表示μ,即均值,1表示σ,即标准差
一组随机数,大部分接近均值0,小部分超出正负一个标准差的数,称为高斯噪声
扩散模型
往水里滴一滴墨水,墨水在水中会扩散开了(布朗运动)。扩散指物质例子从高浓度往低浓度移动的过程
一堆花粉,足够长的时间扩散出一团,就是高斯分布,也就是正态分布
而扩散模型受此启发,通过往图片加入高斯噪声模拟这一过程,并通过逆向过程从随机的噪声中生成图片
时光倒流
时间往回推,就会更靠近初始位置一点,正向是无序的,但是反序就变回有序的(熵增删减),我们需要一个向量场(score function),类似一个导航,指引杂乱无章的例子逐渐靠近源头。

这与图片生成有什么关系?
生成图片,本质就是让一堆无序的粒子,排成有序的队形。一个图片比
前向加噪
RGB表示的图片,每个像素都一个rgb
$$
\mathbf{x}_t=\sqrt{\bar{\beta}_t}\mathbf{x}_0+\sqrt{1-\bar{\beta}_t}\epsilon
$$
调整β,逐渐增加,使得加噪比例越来越大,e是服从标准正态分布重新采样的随机数
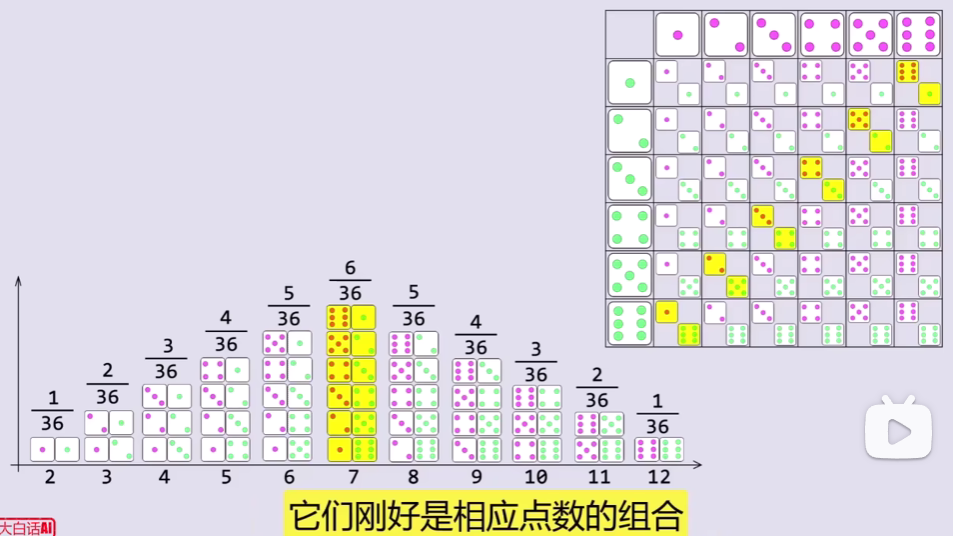
不需要罗列,只需要两个序列方向匹配,不断平移对齐,分别计算出上下点数各组合的概率,求和就得到了响应总点数的概率,叫卷积
对两个概率分布进行卷积操作,实际上就是计算两个分布所有组合的情况,得到叠加后的概率分布。卷积后的概率密度仍符合正态分布
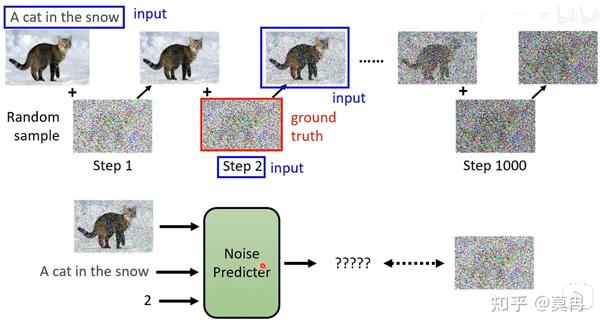
如何理解通过Diffusion从文本到图像生成的过程?
答:加入文本信息后,实际上最大的改变就是在噪声预测的时候加入了一个新的输入,即文本。这里我们可以和条件GAN对比来理解。
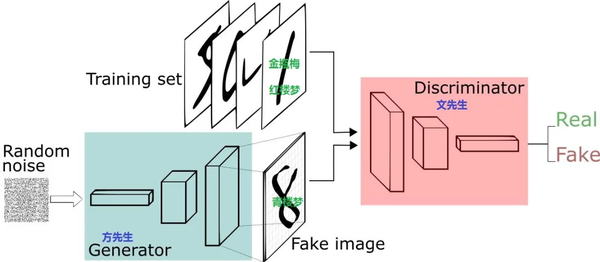
GAN
损失函数
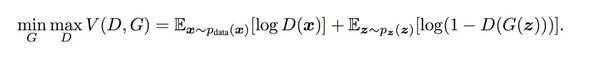
V(D,G)表示的是生成样本和真实样本的差异度,可以使用二分类(真、假两个类别)的交叉熵损失。
目的就是让生成的图片能够骗过判别器
DALL 3
DALL-E 2 原理
- CLIP文本编码器将图像描述映射到表示空间;
- 然后扩散先验从CLIP文本编码映射到相应的CLIP图像编码;
- 最后,修改版的GLIDE生成模型通过反向扩散从表示空间映射到图像空间,生成众多可能图像中的一个
- 海量数据对
DALL-E 3 改进
- 最大的改进,就是样本质量的提高,其次模型结构微调了(论文未披露),最后就是GPT加持提示词转化精度更高
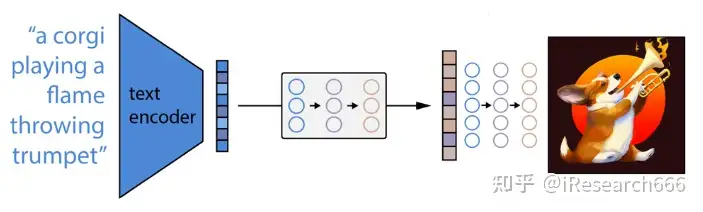
Pytorch
dir()函数,能让我们知道工具箱以及工具箱中的分隔区有什么东西。help()函数,能让我们知道每个工具是如何使用的,工具的使用方法。help(a)或者a??
三个区域编写代码:
- pycharm的python文件
- 整体运行,python文件的块是所有行的代码,适用大型项目
- 每次都是整体运行
- pycharm的python 控制台
- 以任意行为块(Shift+Enter),变量属性在右边查看
- 出现错误可阅读性大大降低
- Jupyter notebook
- 同python控制台,Shift+Enter执行块
- 可以直接修改块中的错误,阅读性加强
- 环境需要配置
加载数据
一堆数据–>Dataset(提供一种方式去获取数据及其label)–>Dataloader(为后面的网络提供不同的数据形式)
Dataset:
- 如何获取每一个数据及其label
- 告诉我们总共有多少数据
数据的组织形式
- 文件夹名就是一个label
- ocr
- 图片
- 对应图片的文字坐标信息
- 图片名就是label
实战案例:
image-Snipaste_2022-09-24_23-31-33
1 | from torch.utils.data import Dataset |
https://cdn.jsdelivr.net/gh/JJuprising/JJuprising.github.io
Tensorboard
看模块的代码:按住Ctrl,点模块
打开窗口,不接--port默认打开6006端口的
1 | tensorboard --logdir=logs --port=6007 |
add_scalar
1 | from torch.utils.tensorboard import SummaryWriter |
重新画删掉Logs文件下下的所有文件,在终端Ctrl+c结束后重新打开窗口
add_image()
opencv读取到的数据是numpy型
从PIL到numpy,需要在add_image()中指定shape中每一个数字/维表示的含义,默认是CHW即通道-高度-宽度,如果导入图片是HWC就要加入说明,见案例:
1 | import numpy as np |
Transform
transform.py工具箱,有toTensor,resize等工具,用于处理图片输出想要的图片结果
- transform的使用
- tensor数据类型
在括号内Ctrl+P查看要输入的参数
tensor数据类型
ToTensor&Normalize
1 | from PIL import Image |
resize()
1 | #接上面代码 |
Compose()
Compose()中的参数需要一个列表。Python中,列表的表示形式为[数据1,数据2,…]。在Compose中,数据需要是transforms类型,所以得到的:
1 | Compose([transforms参数1,transforms参数2,...]) |
将几步打包成一步:
1 | # Compose - resize - 2 |
RandomCrop()
随机裁剪出一部分
1 | trans_random = transforms.RandomCrop(512) |
总结
关注输入和输出
多看官方文档 PyTorch
关注方法需要什么参数
不知道返回值的时候:
- ```python
print()
print(type())
调试1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
## torchvision数据集的使用
官网文档的torchvision.datasets下有很多数据集可以使用
torchvision.models提供训练好的模型
torchvision.transform上面讲了
torchvision.utils提供小工具
```python
import torchvision
train_set=torchvision.datasets.CIFAR10(root="./dataset/data1",train=True,download=True) # 下载训练集
test_set=torchvision.datasets.CIFAR10(root="./dataset/test1",train=False,download=True) # 下载测试集
print(test_set[0]) # ( , )的形式,发现第一个是图片第二个是target
print(test_set.classes) # 查看图片有哪些类型(调式看test_set有calsses属性)
img,target=test_set[0] #接收( , )
print(img)
print(target)
print(test_set.classes[target])
img.show()
- ```python
和transform联动
1 | import torchvision |
结果:

DataLoader
1 | import torchvision |

神经网络
torch.nn,Neural Network。
nn.Module是所有神经网络的基类
1 | import torch |
卷积操作
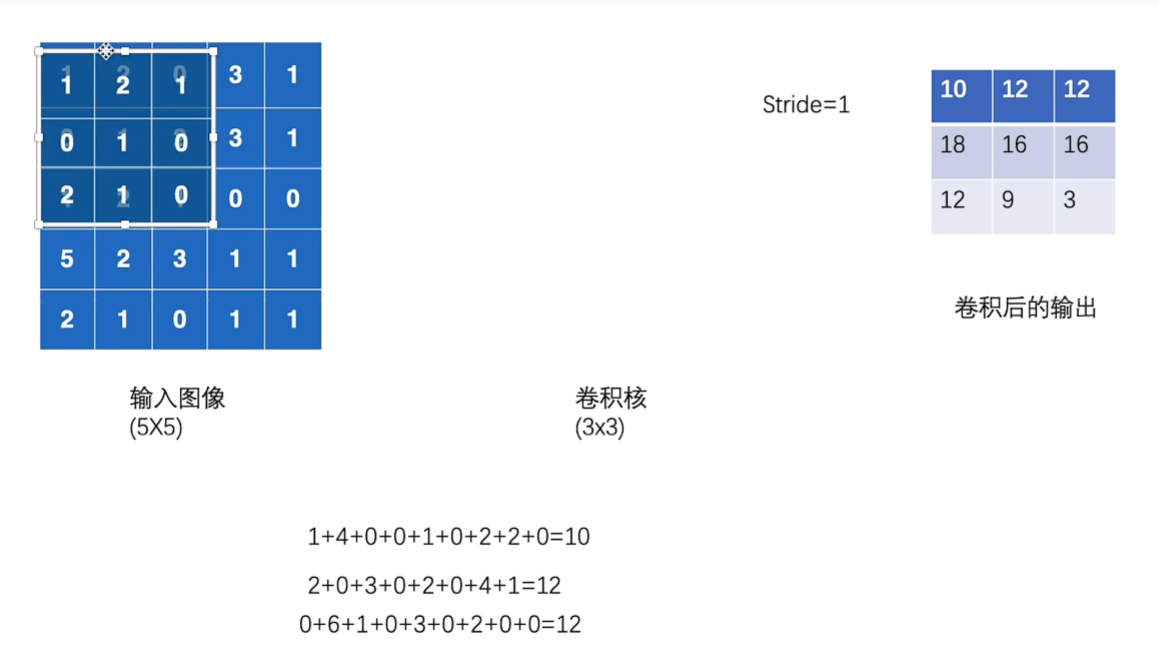
各种参数

Stride
Stirde=1表示卷积核在输入图像上移动一格,对应格相乘得到数;从左到右,到边界回到最左向下移动Stride然后重复操作
padding
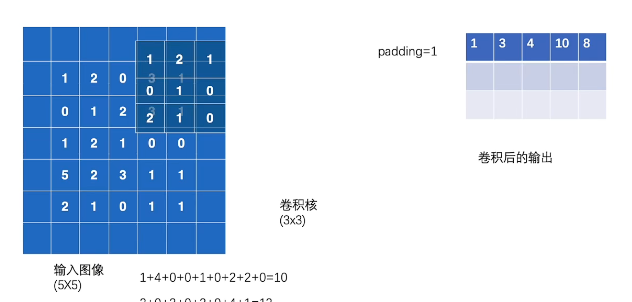
1 | import torch |
卷积层
nn.Conv1d一维卷积,nn.Conv2d二维卷积层…
彩色图像一般是三通道
1 | CLASS torch.nn.Conv2d(in_channels, out_channels, kernel_size, stride=1, padding=0, dilation=1, groups=1, bias=True, padding_mode='zeros', device=None, dtype=None) |
卷积层示例(动图要梯子才能刷出来)
out_channels设置为2时会生成两个卷积核,得到两个叠加的输出。(一般卷积操作会不断增加channels数)
例子:
1 | import torch |

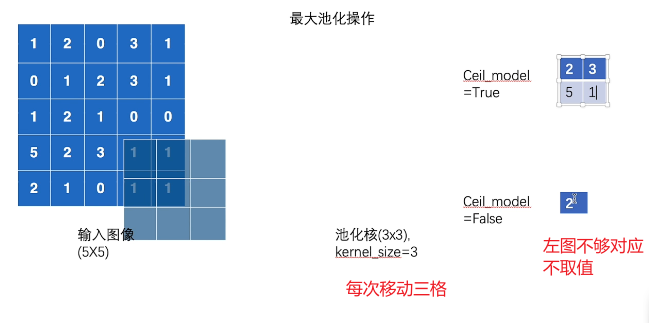
池化层
ceil_mode
floor向下取整,ceiling向上取整。默认false不够对应不取值
实现:
1 | # 最大池化 |
最大池化目的为了保持原先数据的特征同时减少数据量,加快训练速度。例如720p也能大致看明白1080p视频内容
例子:
1 | # 最大池化 |
可以看到输出图片变模糊了
非线性激活 Non-linear
用到ReLu()或Sigmoid()
1 | import torch |

主要目的在网络中引入更多非线性特征,才能训练出符合更多特征的模型。
线性层及其他层
1 | CLASS torch.nn.Linear(in_features,out_features,biass=True) |
biass表示要不要设置偏振b

flattten()展平成一行
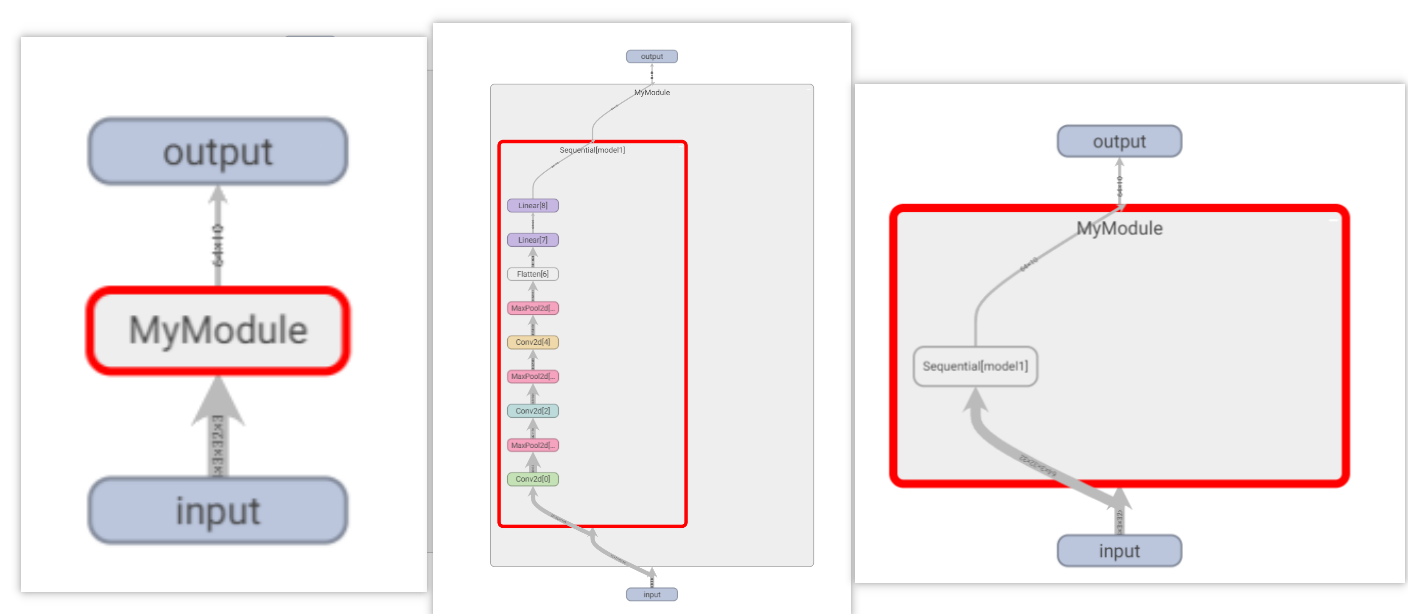
CRAF10小实战及Sequential()

1、由公式计算第一步卷积得到padding是2(默认设置stride为1)

通过对每一步的解析,我们建立出一个简单的模型,代码如下:
1 | import torch |