





1
结论要有量化,或者引人思考的创新点,而不是读完跟不读没区别
图表和公式的引用要根据序号
文章内容用第三人称,不建议用第一,如this paper,it. 主体用一般现在时。
GenAI and Energy流动和运输管理[^1]交通数据增强数据增强是指通过添加对现有数据进行稍加修改的副本或从现有数据中添加新创建的合成数据来增加数据量的技术(Lemley 等人, 2017 年)。
GAN 和 VAE 因其能够生成高质量的合成数据而成为智慧城市数据增强应用中的普遍选择。然而,以去噪和数据增强优势而闻名的生成扩散模型主要用于医学研究而不是城市科学。这表明这些模型在城市应用中有一个潜在的未开发领域,它们独特的能力可以为复杂的城市挑战提供新颖的解决方案。许多先前的研究已经应用 GenAI 模型来增强交通数据。
周等人(2021)引入了轨迹生成对抗网络(TGAN)来解决识别和链接人类移动模式的挑战,特别是在基于位置的社交网络(LBSN)中。这种方法有效地克服了轨迹数据中数据稀疏性和标签分布不平衡的问题,与现有方法相比,TUL 的准确性更高。在这种背景下,使用 GAN 进行数据增强标志着人类移动分析的重大进步,为城市规划和个性化服务等各种应用提供了有希望的意义。
Jilani 等人(2022)提出了一种使用 GAN 进行数据增强的交通拥堵分析的创新方法。该研究引入了一 ...

Promptprompt learning的三个要素,prompt函数,答案空间和从答案到最终结果的映射,其中prompt函数主要利用prompt将原始输入转化为带[MASK](或者占位符)的完型填空格式,答案空间主要用于搜索适合填充到[MASK]位置的候选,而从答案到最终结果的映射主要是根据填充的答案得到最终的预测结果。
Prompt learning系列之answer engineering(一) 人工设计篇 - 文章 - 开发者社区 - 火山引擎 (volcengine.com)
【NLP】Prompt Learning 超强入门教程 (zhihu.com)
文章有提到Prompt工程,有疑问指出DL就是为了避免特征工程,但是Prompt貌似又回到了特征工程。
其实可能不应该说是一个特征工程,而是因为有了LLM,下游任务和预训练的gap消失了(被称为,现代NLP第四范式)。Prompt工程能够将下游任务进行任务重定义,使得所有的NLP任务转变为语言模型问题。
思维链CotCOT通过要求模型在输出最终答案之前,显式输出中间逐步的推理步骤这一方法来增强大模型的算数、常识和推理能力 ...

1马尔可夫决策过程四大基本要件
S状态 state
A 动作 action
R 即时奖励 reward 通常是 a 和 s 的函数
状态间的转换规则 p(s`|s,a) transition probability
对于2048这个游戏的马尔科夫过程:
基本构成
状态:4x4的矩阵,每个值可以是2,4,8,…,2n
动作:上、下、左、右
即时奖励:成功合成的新的数字之和
状态间的转换规则
初始状态是随机生成2在两个格子中
新的砖块随机出现在格子中的一个地方,可能是2或者4,随机概率位置
其他特性:
状态可见性:状态完全可见
转换概率可见性:未知
总奖励:所有即时奖励之和
深度Q学习Q(s,a):在经历状态s后选择了一次a之后总的最佳平均未来奖励。
强化学习(八) - 深度Q学习(Deep Q-learning, DQL,DQN)原理及相关实例-CSDN博客
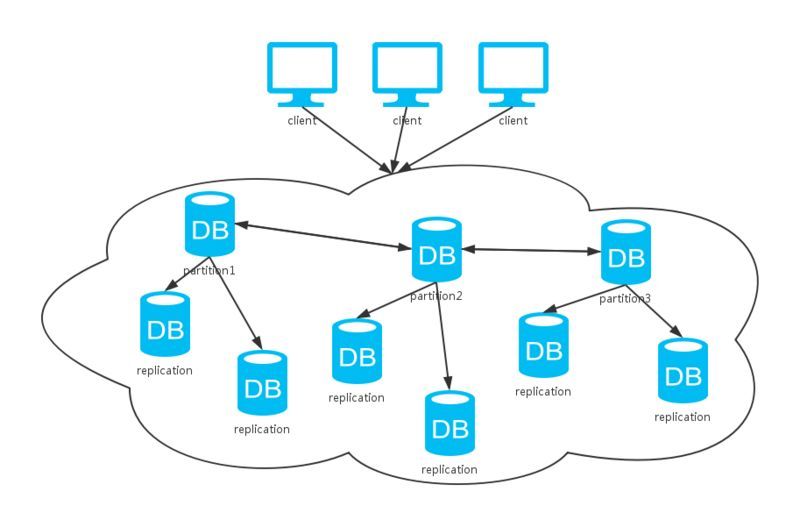
Nginx Nginx:早期由俄国团队开发的可以处理动静分离,处理负载均衡的HTTP反向代理服务器
**反向代理:**反向代理服务器位于用户与目标服务器之间,但是对于用户而言,反向代理服务器就相当于目标服务器,即用户直接访问反向代理服务器就可以获得目标服务器的资源。同时,用户不需要知道目标服务器的地址,也无须在用户端作任何设定。
Nginx作用:动静分离,动态资源访问tomcat,静态资源.html,.js,.css等可以存储在nginx中.
负载均衡:通过nginx决定访问的后端服务器逻辑.
nginx的文件目录
conf:保存nginx配置文件的目录
logs: access.log记录访问nginx的请求,error.log记录启动运行各种错误的日志
如果没有发现nginx进程(nginx.exe),打开logs中error.log,会有错误提示,具体到第几行
停止Nginx: 可在任务管理器中停止进程。
重启Nginx时,要先停止,查看进程是否消失,确定消失之后再运行启动,否则会出现多个nginx的进程相互冲突.
什么是负载均衡负载:服务器承受的访问量压力;
均衡: 物理均 ...

Generative Image Dynamics生成式动力学 Generative Image Dynamics 谷歌团队
扩散模型在视频领域的应用
主要用于建模自然界中的震动、摇摆(oscillatory dynamics)。用频域的方法,在Fourier domain中预测运动;然后通过下游渲染模块根据生成的运动信息赋予静止图片动态。
Demo:
https://generative-dynamics.github.io/#demo
出发点
为了更加形象的视觉合成方法
人类对运动的敏感性会导致没有运动的图像看起来不真实
更真实模拟自然界中物体的运动
Generative Image Dynamics让生成的动图更具真实性
方法输入图片->傅里叶变换->在不同频率下通过LDM模型->图像光谱->通过类似UNet模型生成后续时间的图像
那为啥扯上频率呢?更频率域有什么关系
频域分析的优势是,频域可以把不同的运动通过频域拆解开(比如频率低的运动就是一些缓慢的大范围的运动。频率高的运动就是一些快速范围小的运动),这样就可以对不同运动分别进行分析生成。 ...


目前由于老师习惯用word批注,因此最初都会通过word简历草稿,latex其实在不用大改的情况去成稿是更加方便规范的。Latex的记录在2023年10月就已形成了,可以翻看。而下面一些内容会涉及到word。
关于文献引用,可以看【论文写作】Zotero文献引用技巧 - 知乎 (zhihu.com)
然而,这貌似并不是最完美的办法,因为我发现在正文插入文献后,序号的顺序会乱,本来前面是123好好的,插着插着前面就变成78之类的了。
更新域看看引用是否都正确
用比如Gammerly检查语法,有条件上AI,比如Curie。自己再要看一遍意思对不对,有没有偏差
浏览图片有没有放错图
如何写调研近几年最好的文章。谷歌学术搜索。
入门先看大的综述,0基础就先看中文好的,然后看英文,粗略看。
看技术,十年前是什么算法,十年-五年有什么改进,五年之内又是什么样了。
以此构建自己对这个领域的梳理和认识。
了解这个领域,最牛的团队。后续关注谁,谁有可能跟我的idea撞车。同时,不知道怎么写也知道参考谁的比较靠谱。此外,陶瓷的时候也可以更加有优势,知道人家在做着什么需要什么。
第二阶段描述问题-》缩小问题 ...
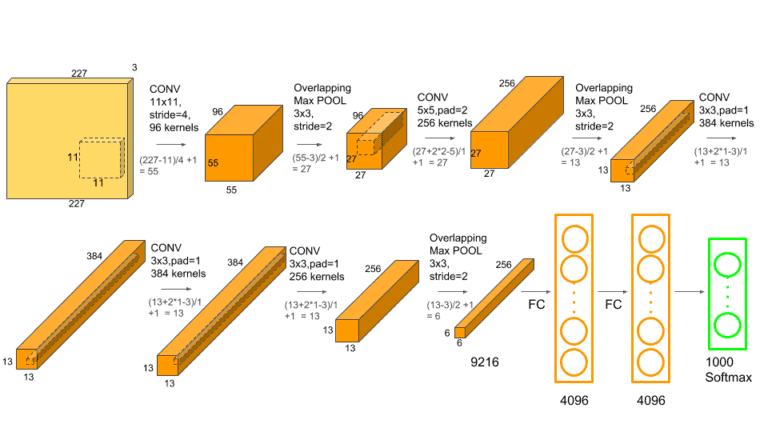
9年后重读深度学习奠基作之一:AlexNet【论文精读·2】_哔哩哔哩_bilibili
读论文
第一遍:题目摘要讨论总结,一些图和公式
BERT无监督
AlexNet之前事无监督,AlexNet有监督
把最后一层的输出向量拿出来对比,在语义空间表示很好
写论文最好不要局限小领域小方向,其他的也要提提公平些。
研究能够让别人往下做是比较好的,而不是纯堆技术做的非常强。
end-to-end端到端,原始图片文本进去,神经网络直接做出来
结构图,维度是输入输出数据大小,中间小块是卷积核
维度长宽逐渐降低降低,一小块表征原始的一大块,而通道不断增加,语义上信息的理解,这个通道理解猫腿,这个理解一个边等
不断压缩,增加语义理解
drop out 正则的东西
sgd机器学习应用广泛的优化算法。weight decay加在模型上,其实就是一个L2正则化
利用均值为0,方差为0.01的高斯分布初始化权重,以后的工作全部初始化为0也不错。BERT是方差为0.02,和模型复杂度有关。
现在用平滑曲线来下降学习率,比如一个cos函数,横坐标是epoch。AlexNet就是每次下降10倍,节点手动 ...

12为了能够管理多台分布式系统,出现了HDFS
Hadoop是一个分布式系统架构
程序员如何编写程序管理,出现了MapReduce,提供了并行框架,map切分,Reduce就是汇总阶段
如何在Hadoop上写SQL,于是出现了Hive,它是一个进行结构化数据处理的解决方案,为了能让用户使用SQL处理数据,S就是结构化。Hive将SQL翻译成MapReduce。
Spark被用来和Hadoop的MapReduce对比。MapReduce是基于磁盘的计算框架,而Spark是基于内存,主打的快。同理也有Spark on SQL
Hadoop基础MapReduce并行计算架构
YARN
HDFS分布式文件系统
HDFS计算机集群
将文件分布存储到多个计算机节点,节点构成计算机集群
计算机集群都是由普通硬件构成,大大降低硬件开销
通过“心跳”判断是否节点损坏,有多个副本,不怕损坏
结构
采用主从结构,有主节点和从节点
一个主节点关联多个从节点,一个从节点关联多个主节点,因此数据在不同从节点中有多个副本
Block-块
windows块大小是4k,而HDFS默认默认一个块128MB,一个 ...


